Nghịch lý xác suất và một số tư duy thống kê sai lầm
Link bài viết gốc tại The Conversation Số liệu xác suất và thống kê đôi lúc có thể khiến ta bối rối | Ảnh tại Shutterstock. ...

Link bài viết gốc tại The Conversation

Số liệu xác suất và thống kê đôi lúc có thể khiến ta bối rối | Ảnh tại Shutterstock.
Nhiều lúc báo đài lại đưa tin rằng thức ăn hay thói quen này nọ tương quan đến sự tăng hoặc giảm nguy cơ mắc bệnh nào đó, hoặc có khi ...lại vừa tăng vừa giảm luôn. Tại sao các cuộc nghiên cứu khoa học nghiêm ngặt lại đem ra nhiều kết quả mâu thuẫn như vậy?
Ngày này, sự tiếp cận với vô số công cụ phần mềm giúp các nhà nghiên cứu có thể phân tích và đem ra kết quả từ nhiều cuộc thử nghiệm thống kê phức tạp. Tuy nhiên, các nguồn tài nguyên thông tin hiệu quả đó đôi lúc lại khiến những ai chưa đủ kiến thức chuyên môn hiểu nhầm một số dữ kiện khó hiểu rồi từ đó đưa ra nhiều kết luận không chính xác.
Dưới đây là một số ngụy luận, nghịch lý thống kê và cách chúng dẫn đến những kết luận khác thường, hoặc - trong nhiều trường hợp - sai bét luôn.
1. Nghịch lý Simpson (Simpson’s Paradox)
a) Nó là gì?
Là khi ta kết hợp xác suất của nhiều sự kiện lại với nhau thì xu hướng của từng sự kiện riêng lẻ sẽ biến mất, khi điều này xảy ra, xu hướng của xác suất tổng hợp đôi lúc có thể mâu thuẫn với xu hướng riêng của mỗi sự kiện
Một ví dụ cho nghịch lý này là khi một phương pháp điều trị sẽ gây hại cho nhóm đối tượng bệnh nhân khi xem xét riêng lẻ, tuy nhiên khi tổng hợp số liệu lại thì lại thấy rằng việc điều trị đó sẽ có lợi.
b) Xảy ra khi nào?
Điều này xảy ra khi số lượng của các nhóm riêng lẻ không đồng đều. Một nghiên cứu vô tình (hoặc cố tình) chọn số bệnh nhân làm sao để có thể kết luận rằng một phương pháp điều trị (thực chất là có hại) trông có vẻ có lợi.
c) Ví dụ
Ta xem xét thí nghiệm mù đôi (thí nghiệm sử dụng phương pháp giảm thiểu định kiến và thiên vị cho người tham gia) về một phương pháp điều trị y khoa được đề xuất sau đây. Một nhóm gồm có 120 bệnh nhân (được chia thành các nhóm nhỏ 10, 20, 30 và 60 người) được điều trị, và một nhóm 120 bệnh nhân khác (được chia thành các nhóm nhỏ tương ứng 60, 30, 20 và 10 người) không được điều trị.
Kết quả tổng hợp cho thấy việc điều trị có lợi cho bệnh nhân, với tỉ lệ hồi phục cao hơn những bệnh nhân không được điều trị.
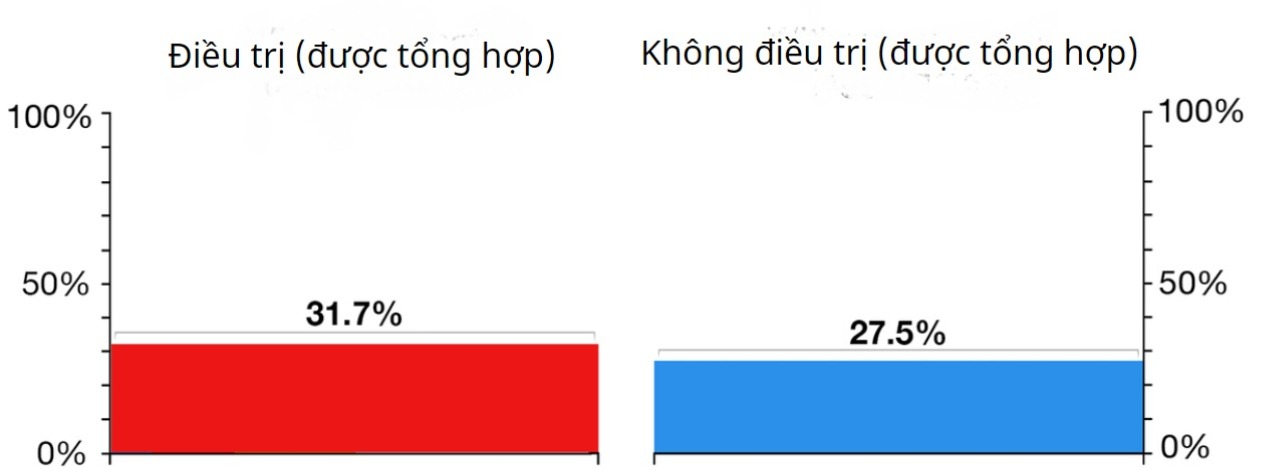
Tất cả biểu đồ đều từ The Conversation
Tuy nhiên, khi xem xét từng nhóm một, ta thấy rằng trong tất cả nhóm bệnh nhân, tỷ lệ hồi phục (cao nhất) của nhóm không được điều trị cao hơn tới 50% (tỉ lệ hồi phục thấp nhất của nhóm được).
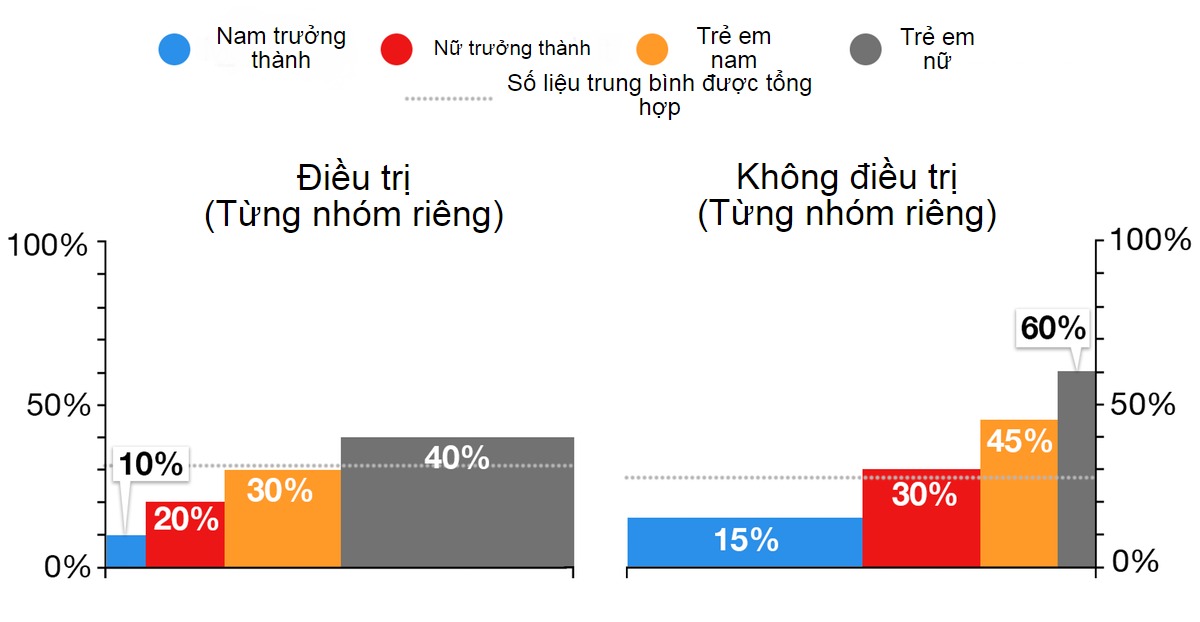
Phải lưu ý một điều rằng hai nhóm được và không được điều trị có sự khác nhau giữa sự phân bố kích thước và độ tuổi. Đây là điều khiến xác suất bị xáo trộn. Trong trường hợp này, nhóm được điều trị có nhiều trẻ em hơn, lứa tuổi dù được hay không được điều trị đều có tỉ lệ hồi phục trung bình cao.
Đọc thêm:
2. Sự sai lầm về tỉ lệ cơ sở (Base Rate Fallacy)
a) Nó là gì?
Sai lầm này xảy ra khi ta không xem xét hết tất cả các khả năng có thể xảy ra của một sự việc/sự kiện.
Giả sử, ta nghe một người nói rằng họ yêu âm nhạc, ta thường nghĩ rằng họ có khả năng là một nhạc sư cao hơn là một viên kế toán. Tuy nhiên có nhiều kế toán hơn là nhạc công ngoài kia. Ta đã chưa xét đến tỉ lệ cơ sở của số lượng kế toán cao hơn rất nhiều so với số nhạc sư, vậy nên đã đánh giá sai từ nguồn thông tin rằng người ấy thích âm nhạc.
b) Xảy ra khi nào?
Sai lầm về tỷ lệ cơ sở xảy ra khi tỷ lệ cơ sở của một khả năng cao hơn đáng kể so với các khả năng khác.
c) Ví dụ
Xem xét một phương pháp xét nghiệm về một căn bệnh hiếm, chỉ 4% (1/25) dân số bị mắc phải.
Giả sử phương pháp xét nghiệm trên không chính xác hoàn toàn. Nếu ai đó mắc bệnh, xét nghiệm sẽ đưa kết quả đúng trung bình khoảng 92%. Nếu ai đó không mắc bệnh, khả năng xét nghiệm sẽ đưa ra kết quả đúng là 75%.
Vậy khi xét nghiệm một nhóm người, ta thấy rằng ¼ người được chẩn đoán dương tính, ta thường sẽ nghĩ rằng phần lớn trong số họ thực sự mắc. Nhưng như vậy sẽ sai đấy.

Trong một xét nghiệm điển hình gồm 300 người, có 11 người được chẩn đoán chính xác là mắc bệnh, trong khi 72 người không mắc bệnh được chẩn đoán sai là mắc bệnh.
Theo như số liệu ở trên, 4% trong tổng số bị mắc bệnh, gần 92% thuộc 4% đó sẽ được chẩn đoán đúng (chiếm 3,67% tổng số người). Nhưng 96% trong tổng số không mắc bệnh, 25% thuộc 96% đó sẽ bị chẩn đoán sai (chiếm 24% tổng số người).
Điều này có nghĩa là khoảng 27,67% tổng số người được chẩn đoán là mắc bệnh, chỉ có khoảng 3,67% mới thực sự mắc bệnh. Vậy nên chỉ có 13% trong số 27% được chẩn đoán đúng là mắc bệnh (nghĩa là 3,67%/27.67%).
Đáng quan ngại thay, trong một cuộc nghiên cứu yêu cầu người tham gia thực hiện các phép tính tương tự như trên để thông báo cho bệnh nhân về nguy cơ chính xác về việc thực sự mắc bệnh so với kết quả chẩn đoán, chỉ 15% trong số đó tính toán chính xác.
3. Nghịch lý Will Rogers ( Will Rogers Paradox)
a) Nó là gì?
Là khi di chuyển một thành tố nào đó từ nhóm này sang nhóm khác sẽ tăng cao giá trị trung bình của cả hai nhóm, mặc dù không có giá trị nào thực sự tăng.
Tên của nghịch lý này bắt nguồn từ danh hài Mỹ Will Rogers, ông đùa rằng “khi người dân ở Oklahoma chuyển đến California, chỉ số thông minh trung bình của cả hai bang đều tăng lên”.
Cựu thủ tướng New Zealand là Rob Muldoon cũng đã chỉnh sửa câu đùa cho phù hợp tại nước mình vào những năm 1980, ám chỉ đến tình hình di cư từ nước ông sang Australia.
a) Xảy ra khi nào?
Khi một thành tố dữ liệu được chuyển từ nhóm này sang nhóm khác, nếu giá trị dưới mức trung bình bị chuyển đi trong khi giá trị trên mức trung bình thì được chuyển vào, con số trung bình của hai nhóm đều sẽ tăng.
c) Ví dụ
Xem xét trường hợp 6 bệnh nhân với ước tính tuổi thọ (tính theo năm) đã được xác định là 40, 50, 60, 70, 80 và 90.
Những bệnh nhân với ước tính tuổi thọ là 40 và 50 được chẩn đoán là mắc bệnh; trong khi 4 người còn lại thì không. Từ đó rút ra rằng tuổi thọ trung bình của bệnh nhân bị chẩn đoán mắc bệnh là 45 năm và của nhóm bị chẩn đoán không mắc bệnh là 75 năm.
Giả sử giờ đây có một phương pháp tiên tiến hơn được phát triển để chẩn đoán bệnh của bệnh nhân có tuổi thọ 60 (nghĩa là bệnh nhân 60 tuổi này giờ thuộc nhóm được chẩn đoán mắc bệnh), thì tuổi thọ trung bình của cả hai nhóm đều được tăng lên 5 năm.

Đọc thêm:
4. Nghịch lý Berkson (Berkson’s Paradox)
a) Nó là gì?
Nghịch lý Berkson có thể khiến ta lầm tưởng rằng có sự tương quan giữa hai biến số độc lập trong khi trên thực tế thì không.
b) Xảy ra khi nào?
Nghịch lý xảy ra khi ta có một nhóm dữ liệu gồm hai biến số độc lập, nghĩa là không có mối liên quan nào giữa hai bên. Nhưng khi nhìn vào tập con của tổng thể, ta có thể lầm tưởng rằng hai biến số có xu hướng tăng giảm ngược nhau.
Điều này có thể xuất hiện khi tập con là các mẫu ví dụ được thiên vị. Trường hợp này đã từng được chỉ ra nhiều trong các thống kê y khoa. Chẳng hạn, nếu một bệnh nhân có triệu chứng lâm sàng với bệnh A hoặc bệnh B, hoặc cả hai bệnh, mặc dù hai căn bệnh A và B đều không liên quan nhau, ta vẫn thấy rằng có sự tương quan (giữa việc mắc một trong hai hoặc cả hai bệnh).
c) Ví Dụ
Xem xét một trường đại học xét tuyển sinh dựa trên hai tiêu chí học lực và năng lực thể thao. Giả sử hai kỹ năng trên đều độc lập khỏi nhau. Nghĩa là trong tổng số sinh viên, tỉ lệ những sinh viên giỏi thể thao nhưng học lực kém cũng bằng với tỉ lệ những sinh viên học lực cao nhưng thể thao kém.
Nếu trường chỉ chọn những sinh viên học lực giỏi hoặc giỏi thể thao, hoặc cả hai, thì ta sẽ nhận thấy rằng trong các học sinh được nhận, kỹ năng thể thao sẽ ảnh hưởng tiêu cực đến học lực và ngược lại.
Để minh họa, ta giả sử rằng mỗi học sinh sẽ được đánh giá năng lực của mỗi kỹ năng dựa trên thang điểm 1-10. Tỉ lệ các thành phần của cả hai nhóm kỹ năng đều sẽ tương tự nhau. Biết được trình độ học lực của ai đó vẫn không cho ta biết được trình độ kỹ năng còn lại của họ và ngược lại.
Giả sử trường chỉ chấp nhận những sinh viên có trình độ 9 hoặc 10 thuộc ít nhất một trong hai kỹ năng.
Nếu ta nhìn vào tổng số thí sinh. Trình độ học lực của những người yếu thể thao nhất cũng bằng trình độ học lực của những người giỏi thể thao nhất (đều 5,5).
Tuy nhiên, trong nhóm các học sinh được nhận, trình độ học lực trung bình của các học sinh giỏi thể thao vẫn là 5,5, nhưng trình độ học lực của các học sinh yếu thể thao lại là 9,5. Điều này xuất hiện mối tương quan tiêu cực không có thật giữa hai kỹ năng.
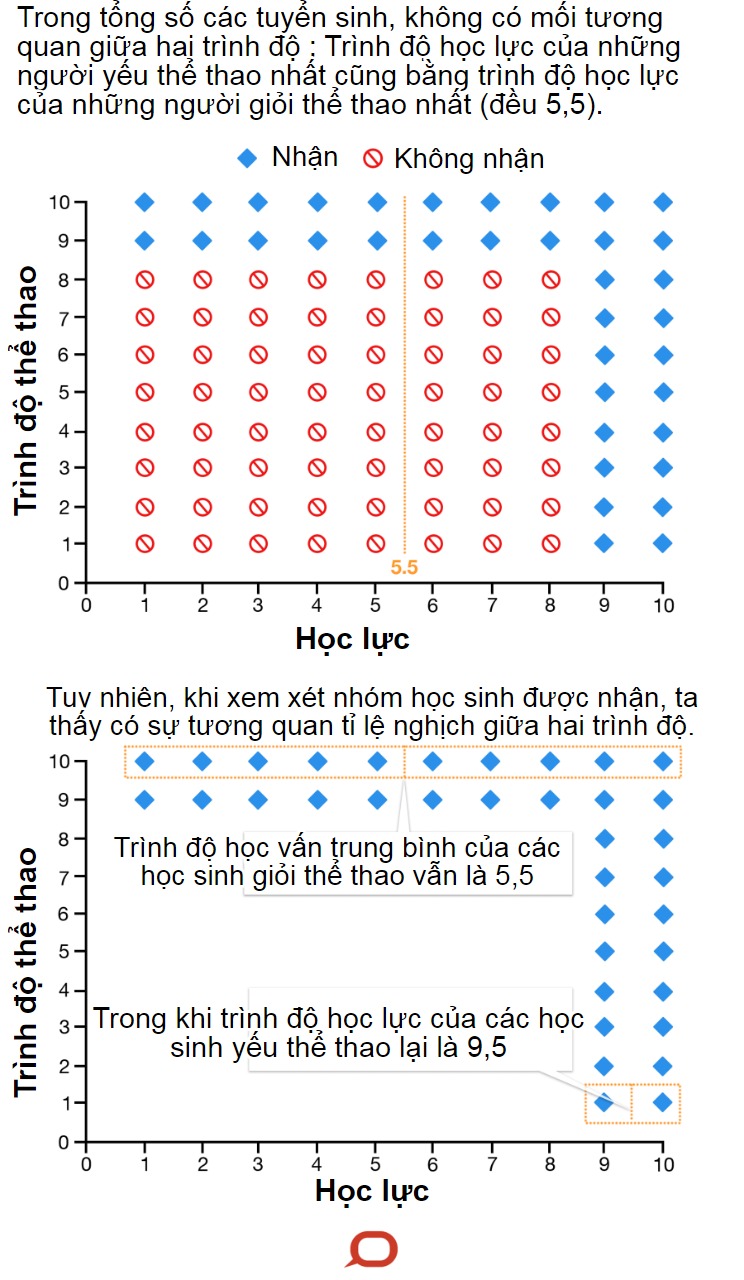
5. Sai lầm về các phép so sánh hàng loạt (Multiple Comparisons Fallacy)
a) Nó là gì?
Đây là khi xu hướng không ngờ tới có thể xảy ra khi thử nghiệm khả năng trong một tổ hợp dữ liệu có nhiều biến cố.
b) Xảy ra như thế nào?
Khi xem xét nhiều biến số và tìm xu hướng chung, sẽ rất dễ xem xét sót một vài xu hướng có thể xảy ra. Ví dụ, với 1000 biến số, có tới gần nửa triệu cặp khả năng có thể xảy ra ngẫu nhiên ( 1000!/2!*998!).
Trong khi mỗi cặp biến cố đều hoàn toàn độc lập, thì các tập biến cố trong tổng số nửa triệu cặp đó sẽ ít độc lập hơn.
c) Xảy ra như thế nào?
Một ví dụ điển hình về sai lầm các phép so sánh hàng loạt là Nghịch lý ngày sinh nhật.
Trong một nhóm gồm 23 người (giả sử mỗi ngày sinh nhật đều là những ngày được chọn ngẫu nhiên một cách độc lập với khả năng trùng nhau tương đương). Khả năng có ít nhất 2 người cùng ngày sinh sẽ cao hơn là không có ai cùng ngày sinh.
Nhiều người thường lầm tưởng rằng việc gặp một người có cùng ngày sinh sẽ rất hiếm. Nếu ta chọn ra 2 người ngẫu nhiên, khả năng để họ có cùng ngày sinh đương nhiên sẽ rất thấp ( khoảng 1/365, thấp hơn 0,3%).

Khả năng không có ai cùng ngày sinh sẽ giảm khi tổng số người tăng lên
Tuy nhiên, với 23 người, sẽ có 253 cặp (23!/2!*21!) có thể cùng ngày sinh. Vậy khi xem xét tổng thể, ta đang tìm xem trong tất cả 253 cặp trên, mỗi cặp sẽ có khả năng trùng ngày sinh là 0,3%, xem có cặp nào trùng ngày sinh không. Các con số khả năng trên của mỗi cặp tổng hợp lại sẽ khiến khả năng trùng ngày sinh tăng lên.
Trong một nhóm trên dưới 40 người, khả năng có cặp chia sẻ cùng ngày sinh cao gần gấp 9 lần khả năng không có ai cùng ngày sinh.
Bài dịch còn nhiều thiếu sót, mong được mọi người góp ý giúp đỡ.
Đọc thêm:

dustsucker
@soulostar
Khoa học - Công nghệ
/khoa-hoc-cong-nghe
Bài viết nổi bật khác
- Hot nhất
- Mới nhất