

[Nhập môn Deep Learning] Representation Learning và giới thiệu về mạng tích chập (CNN)
Cưỡi ngựa xem qua khái niệm Representation Learning và giới thiệu ngắn về mạng tích chập CNN

Ở phần trước, cảm ơn độc giả @WandererGuy đã gợi ý topic Representation Learning. Nhờ đó, tôi thử diễn đạt khái niệm này dưới ở mức nhập môn trong bài này. Tuy nhiên, để thực sự đạt được đến các nghiên cứu ngay hiện tại cần một chặng đường dài hơn. Vì thế, tôi chỉ tạm thời giới thiệu sơ lược cũng như giải thích concept cơ bản của representation learning. Sau đó, lấy đà và đi tiếp đến giới thiệu về mạng tích chập (CNN) trong phần này.
Mạng neural thần kinh nhân tạo có thực sự suy nghĩ?
I think, therefore I am - DecartseMạng thần kinh nhân tạo có suy nghĩ được hay không?
Con người suy nghĩ như thế nào là một điều kì bí. Nên về mặt sinh học (khoa học thần kinh), một định nghĩa rõ ràng cho việc suy nghĩ (thinking) vẫn còn là đề tài chưa đi tới thống nhất. Vậy còn về mặt triết học, suy nghĩ cũng tương tự là một vấn đề nan giải. Mặc dù vậy, tuỳ vào định nghĩa về “suy nghĩ” mà ta có thể nói mạng thần kinh có thể suy nghĩ hay không. Chẳng hạn, nếu ta nói việc tiếp thu kích thích thần kinh, xử lý dữ liệu, đưa ra kết quả là suy nghĩ, thì hẳn máy tính đã có thể suy nghĩ từ rất lâu, không cần phải đợi đến thời đại của neural network. Tuy nhiên, nếu lấy con người làm quy chiếu, thậm chí là động vật có não với các neural synaps thôi thì cách mà máy tính (mạng neural) hoạt động vẫn rất khác. Chẳng hạn, khi ngửi thấy mùi thơm quen thuộc, bộ não trực tiếp tái tạo một loạt các phản ứng sinh hoá trong não bộ, kích thích và tạo ra các xung thần kinh chạy dọc theo nhiều hướng có chọn lọc (đã liên kết) và có thể tái tạo hàng tá thứ: ví dụ một căn phòng quen thuộc, người mẹ, thậm chí cảm giác hãnh diện nếu cái mùi đó gắn với một dịp huy hoàng nào đó trong cuộc đời bạn. Ta hãy gọi quá trình này là “cognition”. Thay vì vậy, máy tính chỉ đơn giản là phân tích tất cả mọi thứ có thể từ mùi hương, tính toán dựa trên các thông số có sẵn, đưa ra kết quả theo một flow cố định. Quá trình này được gọi là “computation”. Bản thân tôi không cho rằng hai quá trình này là giống nhau và theo phe của [1]. Nhưng mà ai nói là chỉ có suy nghĩ như con người thì mới là suy nghĩ. Thế thì đành phải chờ các nhà khoa học thần kinh cũng như các nhà triết học tiếp tục phát triển câu hỏi này. Một tư tưởng lớn trong ngành AI cũng công nhận việc AI không có quá nhiều “self-awareness” trong một bài phỏng vấn nhân dịp đạt giải Nodel vừa rồi. Anw, from a brain to a mind is far more complicated, but not impossible.
Nhưng có một vấn đề cơ bản mà có lẽ ta có thể đi đến kết luận ở hiện tại đó là sự khác nhau giữa cách học của mạng thần kinh và cách học của não bộ con người [2]. Ở chương trước, tôi trình bày một phương pháp học của mô hình học sâu dựa trên việc tìm điểm tối ưu cục bộ (local minima) trên một hàm có đầu vào là kết quả của mô hình và nhãn (label) đúng của dữ liệu. Nếu kết quả dự đoán là con chó, giống với nhãn thì là tốt, không giống với nhãn thì chưa tốt. Quá trình huấn luyện có tham chiếu như thế được gọi là Supervised Learning. Nhưng con người hoặc các trí thông minh ngoài tự nhiên không học như thế. Chúng ta có sẵn những kiến thức trong gen được truyền lại từ tổ tiên âm thầm hỗ trợ việc học (e.g. học ngôn ngữ [3], etc.). Chúng ta học từ môi trường theo cách thụ động nhiều hơn là trực tiếp. Cái chúng ta học được là concept, tính chất, đặc điểm, etc. của sự vật hiện tượng. Ví dụ, chúng ta có thể thiết lập một hệ vật lý để tưởng tượng quỹ đạo khi ta ném một quả táo. Hiện tại, máy tính không thể tự làm được điều đó, thậm chí học cũng chưa được*. Ví dụ dễ thấy là các video sinh bởi AI thường có các sự ngớ ngẩn về mặt vật lý. Tuy nhiên, một trí thông minh nhân tạo phải có khả năng hiểu được thế giới xung quanh nó [4]. Tức là, nó phải “hiểu” được sâu hơn vấn đề, định nghĩa/định hình/nhận dạng (identify) và phân tách (disentangle) các nhân tố của đối tượng đích. Khi đã “hiểu” (nắm bắt) được nhiều vấn đề hơn, mô hình sinh ra khả năng suy luận, tăng khả năng biểu diễn, dự đoán, etc.
Từ nhu cầu đó, một nhánh nghiên cứu có tên là “representation learning” ngày càng nhận được nhiều sự quan tâm của cộng đồng và phát triển cực kì mạnh. Representation Learning, đúng như tên gọi, là nhánh nghiên cứu về việc giúp các mô hình học máy, đặc biệt là học sâu, có thể học được các biểu diễn (representation) có ích hoặc có nghĩa theo hướng nào đó. Thậm chí, hội nghị “representation learning” quốc tế (International Conference of Learning Representaions) trở thành hội nghị uy tín và thu hút hàng đầu của giới nghiên cứu AI hiện đại.
Nhưng mà, “biểu diễn” cụ thể là cái gì?
*ở đây, tôi loại trừ các mô hình/phần mềm giả lập được thiết lập với rất nhiều thông số, tính toán dựa trên các công thức vật lý. Từ lý thuyết, chúng đã không phải là các trí thông minh nhân tạo (AI) mà là thực tế ảo (AR)
Biểu diễn (Representation)
Tôi sẽ bắt đầu câu chuyện từ chữ “Deep” trong Deep Learning. Bản thân mô hình Deep Learning luôn là xếp chồng của rất nhiều lớp (layers) hoặc các modules. Ở các bài viết trước, tôi chỉ đề cập đến kết quả cuối cùng của mô hình, tức là kết quả của lớp cuối cùng (hoặc phức tạp hơn một chút tuỳ vào mô hình cụ thể). Phần còn lại, các kết quả của các lớp ở giữa, hay còn gọi là intermediate layer hoặc được gọi là hidden layer, được đặt tên là intermediate representation, hidden representation, và hidden feature, etc. Chính ở đây, cụm từ representation xuất hiện, từ này cũng được dùng cho kết quả cuối cùng của mô hình. Như vậy, các quá trình học khiến cho các representation này có nghĩa theo hướng nào đấy như đề cập ở phần trước thì đều được liên kết đến representation learning. Tốt nhất, chúng nên phản ánh bản chất, định dạng, hoặc có thể giải thích cho tối tượng đầu vào.
Cụ thể, bản thân các biểu diễn này chính là các vector đại số trong không gian vector nhiều chiều. Trong trường hợp là ma trận, hoặc tensor, thì cũng chỉ là tập hợp các vector đại số. Các vector đại số biểu diễn (representation vector) này trở lên có nghĩa khi nó có thể thông qua hướng và độ lớn của nó để chỉ ra tính chất nào đó. Ví dụ, vector biểu diễn của hình ảnh một con chó (vector C1) và vector biểu diễn hình ảnh của một con mèo (vector M) sẽ có khoảng cách xa hơn so với khoảng cách từ vector C1 đến vector C2 là biểu diễn của một con chó khác. Lý do là giữa hai con chó thì phải giống nhau hơn là một con chó so với một con mèo. Hay như [6] chỉ ra rằng các mô hình ngôn ngữ lớn thường có xu hướng mã hoá nghĩa của từ vào hướng của một vector trong không gian vector nhiều chiều. Để dễ hiểu, tôi sẽ thử mô hình hoá đơn giản câu nói này như sau:
Ta gọi quá trình mã hoá là hàm E() với đầu vào là một từ bất kì. Như vậy, vector biểu diễn khi mã hoá từ “phụ nữ” là E(phụ nữ), tương tự các từ “đàn ông”, “cô”, “chú”. Về mặt ngôn ngữ, ta dễ thấy quá nếu tương ứng với “phụ nữ” là “cô” thì tương ứng với “đàn ông” sẽ là “chú”. Vậy thì, các vector biểu diễn của các từ trên cũng phải biểu diễn được mối tương quan này. Đến đây, mời bạn đọc nhớ lại một chút kiến thức cộng trừ vector. Hãy chú ý rằng phép tính vector thì có liên quan tới chiều và độ lớn. Và phương trình sau đây chính là mối tương quan của các vector được mã hoá.
E(đàn ông) - E(phụ nữ) + E(cô) = E(chú)

Hình 1. Biểu diễn vector mã hoá được từ các từ phụ nữ, đàn ông, cô, và chú. (Làm ơn tưởng tượng hai vector màu xanh lá song song, tôi không giỏi dựng hình 3D lắm)
Ta hãy thử phân tích phép tính trên một chút. Kết quả của phép tính E(đàn ông) - E(phụ nữ) là một vector có hướng và lượng để chỉ ra khoảng cách của hai vector biểu diễn tương ứng. Vì ta giả thiết rằng tương quan của hai từ này sẽ bằng với tương quan giữa từ cô và chú. Vì thế, nếu cộng vector khoảng cách đó vào vector E(cô) thì sẽ được kết quả là E(chú), như trình bày trong Hình 1.
Tương tự như vậy, độc giả thử đoán xem: E(German) - E(Italy) + E(Hitler) thì kết quả sẽ là gì?
Kết quả tương tự cũng có thể tìm thấy ở các mô hình học sâu về tiếng nói. [7] chỉ ra rằng các âm phát âm gần giống nhau thì có biểu diễn trong không gian vector gần nhau và ngược lại với các âm phát âm rất khác nhau. Điều này rất rõ ràng về dễ hiểu đối với con người khi phát âm “a” và “ă” khá giống nhau nhưng “a” và “b” lại rất khác nhau.
Thêm một ví dụ, vào ngày 12 tháng 12 (hai ngày trước khi tác giả bắt đầu viết blog này), Meta vừa đăng tải 1 bài nghiên cứu về Large Concept Model như là một bản nâng cấp của Large Language Model. Representation mà mô hình này hướng đến chính là “concept” trong từng câu thay vì từng từ hoặc cụm từ như các mô hình ngôn ngữ lớn trước đó. Nhờ đó, quá trình reasoning của trở lên được phát triển trên mức “câu” (concept) dẫn đến khả năng làm việc của mô hình được cải thiện hơn nữa. Hình. 2 là một ví dụ cho việc tóm tắt một đoạn văn 5 câu (chấm màu hồng/xám (tác giả bị mù màu nhẹ không phân biệt được)) thành 2 câu (chấm màu xanh dương).
![Hình 2. Tóm tắt văn bản bên trái thành 2 câu như bên phải thông qua biểu diễn vector. Hình từ [5]](https://images.spiderum.com/sp-images/887a42e0ba3d11efacd64965f9960f6f.png)
Hình 2. Tóm tắt văn bản bên trái thành 2 câu như bên phải thông qua biểu diễn vector. Hình từ [5]
Thêm nữa, một khi mô hình có thể học được cách biểu diễn các concept rồi thì ta có thể tận dụng các mô hình đó để ghép các concept với nhau để tạo ra thứ chưa từng có, ví dụ như hình chú chó phi hành gia đang bay ngoài vũ trụ, hoặc là hình dưới đây.

Hình 3. Hình sinh bởi MidJourney. Tác giả: Shanye_wandusheng_96159. Prompt: Paper cut style.The lovely Santa Claus is lying on the roof with presents. The stars are shining all around. The house is big and the house is warm. //// Chú thích nhỏ: Bản thân từng câu, được tách nhau bởi dấu ‘.’ sẽ là một concept. Các concept này vốn riêng biệt, có thể đã xuất hiện trong dữ liệu. Nhờ việc học được các concept riêng này, người ta sử dụng nhiều kĩ thuật để tạo hướng dẫn mô hình sinh (generative model) tạo ra bức ảnh (lần đầu có trên đời). Sẽ có tranh cãi về vấn đề đạo đức (e.g.: đạo tranh), nhưng bản thân tôi không cho rằng như vậy. Vấn đề sẽ tương tự như câu hỏi: Liệu Levitan có đạo tranh của Monet hay không?
Thậm chí là các video như thế này:
Phía trên là giải thích ngắn gọn (có phần còn hơi khó hiểu) cho người đọc về Representation Learning. Nói tóm lại, việc dạy cho mô hình “hiểu” được thế giới xung quanh thông qua các “biểu diễn” có khả năng biểu diễn tính chất, ý nghĩa, etc. của đầu vào thì được gọi là representation learning. Việc này có thể nói là vừa khó vừa dễ. Dễ là chỉ cần tải code có sẵn chạy là được. Khó là hiểu được thực tế quá trình này diễn ra như thế nào, làm sao để dạy cho nó ngày càng tốt hơn, học được cái có ý nghĩa, etc. Bạn đọc có thể tham khảo qua các bài báo đang được open review cho hội nghị ICLR 2025 sắp tới tại đây để xem thêm các hướng đi cũng như hướng áp dụng của representation learning. Đây cũng là một mảng vừa rộng lớn, vô tận, sâu hun hút như một vũ trụ mà bản thân tôi chưa muốn đưa độc giả lún chân vào. Vì thế, bài viết này chỉ nhằm dắt độc giả cưỡi ngựa thưởng hoa. Để độc giả biết đến một khái niệm như thế. Phần nào, cũng giúp diễn giải các thuật ngữ, lý thuyết tiếp theo đơn giản hơn.
Người viết nhận thấy có thể dễ dàng hơn giải thích về khái niệm representation learning thông qua hình dưới đây. Bạn đọc hãy thử hình dung về những thứ cấu tạo lên khuôn mặt. Chúng ta sẽ có: mũi, mắt, lông mày, miệng, môi, tai, etc. Đấy chính là những hình ảnh trong phần hình phía trên. Chúng là phần hình ảnh mà một lớp chưa sâu ở một mô hình học sâu học được sau khi được huấn luyện trên một tập dữ liệu toàn là những khuôn mặt [8]. Phần phía dưới là những thứ mà mô hình học được ở lớp sâu hơn. Đúng vậy, chúng là những khuôn mặt gần hoàn chỉnh. Những concept từ cơ bản đến phức tạp được học dần dần theo chiều sâu của mạng neural này. Điều đặc biệt ở đây là để giúp cho mô hình họ được những “hiểu biết” này, một building block có thiết kế đặc biệt đã được áp dụng. Đó là mạng thần kinh tích chập (convolutional neural network) hay còn được gọi tắt là CNN. Ta sẽ bàn đến lý do mà mô hình sử dụng CNN lại có khả năng học được các concept mắt, mũi, miệng… như thế ở phần tiếp dưới đây.
![Hình 4. Kết quả học được từ một trong những layer đầu tiên (phần phía trên) tới các layer ở sâu hơn (phần phía dưới. Hình từ [8].](https://images.spiderum.com/sp-images/1204d520ba3e11efb8218b3d053efa2d.png)
Hình 4. Kết quả học được từ một trong những layer đầu tiên (phần phía trên) tới các layer ở sâu hơn (phần phía dưới. Hình từ [8].
Mạng thần kinh tích chập
![Hình 5. Kết hợp hình một chú gấu với phong cách vẽ của Van Gogh. Hình từ [9]](https://images.spiderum.com/sp-images/5e0eed70ba3e11ef953597b5d2ab8dbb.png)
Hình 5. Kết hợp hình một chú gấu với phong cách vẽ của Van Gogh. Hình từ [9]
Bắt đầu từ phép toán tích chập
Điều gì xảy ra nếu ta tìm cách chập (chập trong từ “chồng chập”) hai thứ vào nhau như hình trên: một con gấu và phong cách vẽ của Van Gogh. Một cách trực giác, nó sẽ có kết quả có tính chất của cả hai mà ta mong muốn: một con gấu được vẽ theo phong cách của Van Gogh. Đây chính là ý nghĩa chính của phép toán tích chập. Bây giờ, ta có hai hàm sẽ bất kỳ, có nhiều cách để ta “chập” chúng vào nhau, một trong số đó là nhân (tích) chúng lại với nhau. Thế là chúng ta có phép toán tích chập. Một cách chính xác hơn, hãy tham chiếu vào hình bên dưới, ta sẽ dùng lấy một hàm màu vàng, trượt trên trục x từ âm vô cùng đến dương vô cùng.
Mỗi khi trượt đến vị trí t bất kì trên trục x (trục hoành), ta nhân giá trị của hai hàm xanh và vàng tương ứng mỗi điểm thì ra được hàm màu đỏ. Sau đó, ta cộng tổng của tất cả các giá trị của hàm màu đỏ dọc theo trục hoành thì sẽ được hàm kết quả ở bên dưới tại điểm t (chấm màu đỏ).

Hình 6. Tích chập của hai hàm xanh và vàng ở phía trên cho ra kết quả là hàm ở phía dưới.
Để chính xác, hãy đọc thử phân tích công thức của hàm tích chập sau đây:

Một nhận xét dễ thấy ở đây đó là tại thời điểm $t$ mà hai hàm có càng nhiều điểm chung thì kết quả của phép tính càng lớn tại điểm $t$ đó. Hay nói cách khác, chỉ bằng tính toán, ta có thể biết đại khái được một số sự giống nhau tại địa điểm cụ thể trên một hàm số cố định với một hàm số được trượt liên tục. Ví dụ trực quan hơn, ta cầm một cái khuôn hình đôi mắt rà khắp một bức hình. Nếu bức hình đó là một khuôn mặt, thì sẽ có một điểm nào đó ta tìm được rất nhiều điểm chung giữa khuôn hình đôi mắt và cái hình ta đang rà soát. Đó chính là ý tưởng của Hình. 4. Và cụ thể thì mô hình học sâu được dùng trong thí nghiệm đó chính là được tạo thành từ CNN.
Convolutional Neural Network (CNN)
*Hình ảnh của phần này sẽ được lấy từ [9] theo MIT license được nêu trong opensource của tác giả.
Một mạng CNN truyền thống thường có các thành phần: convolutions, pooling, và fully connected (tên gọi khác của MLP mà không có hàm kích hoạt, cụ thể là nối tất cả các nodes phía trước với các nodes ở phía sau, fully connected!).

Hình 7. Các thành phần của một mạng CNN
Tích chập (Convolutions)
Hãy nhớ lại phép toán tích chập ta vừa bàn ở phía trên. Với dữ liệu bất kì (hình ảnh, âm thanh, video, thậm chí là văn bản chữ viết), ta dùng một vector/matrix/tensor (còn gọi là kernel) có độ rộng (kernel_size) trượt trên 1 hướng cố định, mỗi lần trượt đi số ô (stride) cố định, tích chập (nhân các ô tương ứng giữa kernel với vùng trên ảnh rồi tổng lại). Thêm nữa, nếu trượt một hướng cố định thì được cọi là convolution 1D (1 dimension), trượt trên hai hướng như hình dưới thì được coi là convolution 2D (2 dimensions), tương tự cho 3, 4 chiều, etc. Kết quả của phép này có tên gọi là feature map hoặc activation map.

Hình 8. Tích chập 2 chiều. Trong trường hợp cái hình này không động đậy, hãy click vào đây
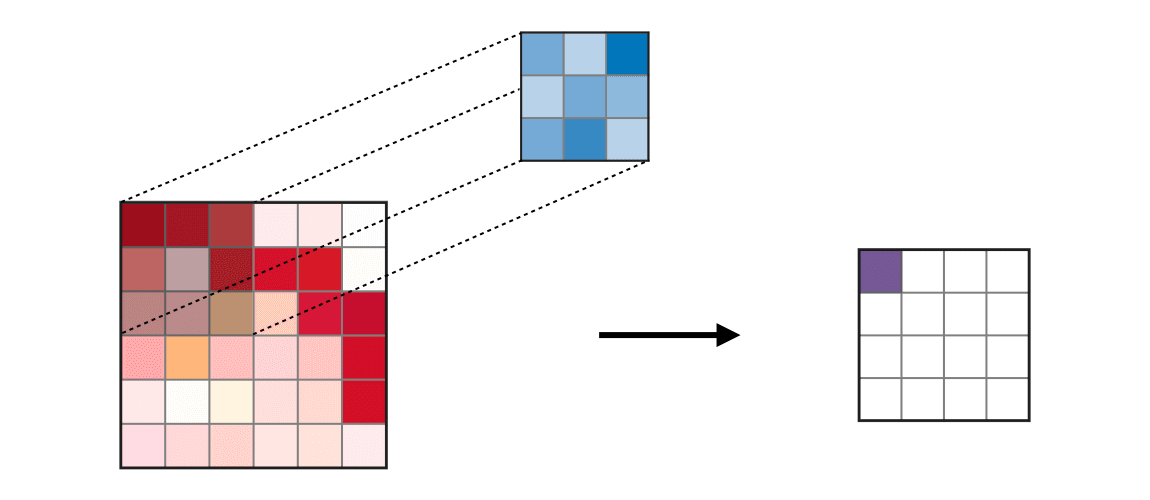{kind=link}
Pooling
Phép toán pooling chỉ đơn giản là phép downsampling (thu gọn) một hình ảnh hoặc một feature map bằng cách tính ra một kết quả đại diện cho một vùng bằng phép tính trung bình, hoặc max. Nó giống như biến một bức hình to thành một bức hình nhỏ hơn bằng cách trượt một phép tính avg hoặc max như trong hình [9].

Hình 9. Average Pooling. Trong trường hợp cái hình không động đậy, vui lòng click vào đây
{kind=link}
Như đã giải thích ở phần đầu, fully connected chính là MLP mà không có activation function, hay có thể nói là một phép biến đổi tuyến tính. Cũng giống như trình bày ở bài đầu tiên, một phép biển đổi tuyến tính không có quá nhiều ý nghĩa. Tuy nhiên, đừng quên những hàm kích hoạt, ví dụ như ReLU. Nhờ có các hàm kích hoạt mà các kiến thức học được dần đa dạng hơn. Dưới đây là một ví dụ từ Polo Club: https://poloclub.github.io/cnn-explainer/.

Hình 10. Hãy chú ý các tên gọi từ trái qua phải ở phía trên. Các ký hiệu conv, relu, max_pool tương ứng là convolution, relu, pooling bằng hàm max. Bạn đọc hãy thử đọc và tưởng tượng ra mô hình là hình trên biểu diễn.
Qua ba khái niệm trên, người đọc thể hiểu và biết cách đọc một mạng CNN cơ bản, tuy nhiên, để tạo ra một mạng CNN thì không chỉ cần các khái niệm trên mà cần hiểu thêm một số kĩ thuật nữa. Tuy nhiên,…
Đến đây, tôi xin tạm dừng lại phần về CNN và hẹn đọc giả ở phần tiếp theo để giải đáp cũng như thử code và huấn luyện một mạng CNN. Vì là thời gian cuối học kì cũng như cuối năm, bản thân tôi thì lực bất tòng tâm, thật không thể tiếp tục viết sâu hơn về CNN.
Kết luận
Ở phần này, tôi đã giới thiệu Representation Learning, giải thích và đi qua vài ví dụ cho người đọc có cái nhìn cơ bản về vấn đề này. Tiếp đến, tôi chọn giới thiệu về CNN để tiếp tục mở rộng khái niệm reprensetation learning trên hình ảnh nhằm đạt được sự trực quan trên hình ảnh.
Còn nhiều phần cần bàn đến khi nhắc đến CNN như một số thông số khác: dilation, groups, receptive field, etc. Hoặc như tên gọi kernel từ đâu mà ra, bản chất toàn học sâu xa hơn… Thậm trí ngay cả việc hiện thực hoá tính toán hàm này trên ngôn ngữ lập trình cũng rất thú vị. Nếu trượt từng bước như vậy thì sẽ rất tốn thời gian, làm thế nào để tận dụng khả năng tính toán song song? Các câu hỏi này sẽ được giải đáp kỹ hơn ở phần tiếp theo. Cảm ơn đã đọc đến đây.
References
[1] Weimer WB. Cognition is not computation, for the reasons that computers don’t solve the mind-body problems. Behavioral and Brain Sciences. 1980;3(1):152-153. doi:10.1017/S0140525X00002284
[2] Song, Y., Millidge, B., Salvatori, T. et al. Inferring neural activity before plasticity as a foundation for learning beyond backpropagation. Nat Neurosci 27, 348–358 (2024). https://doi.org/10.1038/s41593-023-01514-1
[3] Staes, N., Sherwood, C.C., Wright, K. et al. FOXP2 variation in great ape populations offers insight into the evolution of communication skills. Sci Rep 7, 16866 (2017).
[4] Bengio, Yoshua, Aaron Courville, and Pascal Vincent. "Representation learning: A review and new perspectives." IEEE transactions on pattern analysis and machine intelligence 35.8 (2013): 1798-1828.
[5] LCM team, Loic Barrault, Paul-Ambroise Duquenne, Maha Elbayad, Artyom Kozhevnikov, Belen Alastruey, Pierre Andrews, Mariano Coria, Guillaume Couairon, Marta R. Costa-jussa, David Dale, Hady Elsahar, Kevin Heffernan, Jo\~{a}o Maria Janeiro, Tuan Tran, Christophe Ropers, Eduardo Sánchez, Robin San Roman, Alexandre Mourachko, Safiyyah Saleem, Holger Schwenk. Large Concept Models: Language Modeling in a Sentence Representation Space. Arxiv 2024.
[6] Mikolov, Tomas. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 3781 (2013).
[7] Belinkov, Yonatan, and James Glass. "Analyzing hidden representations in end-to-end automatic speech recognition systems." Advances in Neural Information Processing Systems 30 (2017).
[8] Lee, Honglak, et al. "Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations." Proceedings of the 26th annual international conference on machine learning. 2009.
[9] Shervine Amidi. “Convolutional neural network cheatsheet”. https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks

thefour
@datnguyen_bk
Khoa học - Công nghệ
/khoa-hoc-cong-nghe
Bài viết nổi bật khác
- Hot nhất
- Mới nhất