
Các "biểu đồ lừa dối" thao túng bạn như thế nào (II)
Ở phần đầu tiên, các cậu đã biết được một thủ thuật phổ biến thường được dùng để dựng nên các "biểu đồ dối trá", phần tiếp theo đây...


Ở phần đầu tiên, các cậu đã biết được một thủ thuật phổ biến thường được dùng để dựng nên các "biểu đồ dối trá", phần tiếp theo đây sẽ giới thiệu vài thủ thuật khác.
Phần 1:
2. Axis Manipulation (tạm dịch: điều chỉnh số liệu trên trục)
Một thủ thuật phổ biến khác được sử dụng để bóp méo sự thật trên các biểu đồ là điều khiển cách thể hiện các số liệu trên trục của biểu đồ. Nó được gọi là axis changing trong Data Visualization. Trong thủ thuật này, kẻ tạo biểu đồ có thể thay đổi số liệu trong từng "bước nhảy" được hiển thị trên mỗi trục, từ đó có thể thay đổi hình dáng của đường thể hiện trên biểu đồ. Nếu đơn vị trong từng "bước nhảy" càng nhiều, thì đường thẳng biểu diễn sẽ ít thể hiện sự biến động hơn.
Đây là một thủ thuật rất hiệu quả thường được dùng bởi truyền thông nhằm để truyền tải một khái niệm sai lầm nào đó.
Ví dụ, cậu hãy nhìn vào biểu đồ về biến đổi khí hậu dưới đây được đăng trên tài khoản Twitter của tờ tạp chí National Review:

Cậu có thấy điều gì khác lạ không?
Nếu nhìn kỹ, cậu sẽ thấy có một sự lạ lùng “không hề nhẹ” là trục tung của biểu đồ trên trải dài từ -10 độ đến 110 độ, để làm cho đơn vị trong các bước nhảy tăng lên (mỗi bước nhảy sẽ tương ứng với 5 độ) và khiến cho đường biểu diễn nhiệt độ trở thành gần như là một đường thẳng. Điều này rõ ràng có chủ ý là để quảng bá cái ý tưởng việc trái đất ấm dần lên chỉ là một chuyện hư cấu chẳng hạn, hay tạo scandal để gây chú ý, hoặc cậu có thể nghĩ theo hướng tích cực hơn lâu lâu quý báo đây chỉ muốn thử tài tinh mắt của người đọc thôi. Và thật sự thì “trò đùa” này đã không qua mắt được các độc giả tinh ý của chúng ta.
Và thật may là sau đó thì tờ Quartz đã quyết định vẽ lại biểu đồ trên cho chính xác giúp người đồng nghiệp của họ:

Buồn thật đấy khi cả hai tòa báo quý hóa đây đều có quyền truy cập vào chung nguồn dữ liệu và công cụ phân tích, nhưng chỉ có một bên là chọn cách thể hiện chúng trung thực.
Mình cũng có thể vẽ một cái biểu đồ như thế cho đội Arkansas Razorback yêu quý của mình đấy!
Như thế này này, mình tổng hợp số trận thắng của đội bóng yêu dấu của mình trong vòng mười lăm năm qua rồi vẽ chúng trên một biểu đồ. Nhưng mình bắt chước “trò đùa” của National Review và làm một số điều chỉnh nho nhỏ trên trục tung:

Với mấy cái điều chỉnh này thì đội bóng của mình dường như thắng liền tù tì mà không thay đổi nhiều trong mấy năm qua vậy. Chời má quá đã luôn!
Nhưng nếu cậu quan tâm đến ba cái bóng bầu dục học đường thì cậu sẽ biết là đội yêu dấu của mình không có “đẳng cấp” như vậy, và biểu đồ như thế này mới chính xác:

Ừa thì sự thật là vậy đó, đời không như là mơ...
Một lần nữa nghe này, dữ liệu trong mấy cái biểu đồ này hoàn toàn giống nhau, cùng thể hiện trong một loại biểu đồ giống nhau, nhưng đến cuối cùng chúng lại kể hai câu chuyện khác nhau mới ghê.
Chời đất thay đổi nhanh như lật bánh tráng vậy. Và cậu nên sợ đi là vừa. Bởi vì thủ thuật này còn được dùng trong một loạt mấy thứ đao to búa lớn khác như chính trị, truyền thông, thương mại để tuyên truyền nữa.
3. Cherry Picking Data (tạm dịch: lựa trái anh đào)
Một cách khác nữa để dựng lên mấy cái "biểu đồ lừa dối" là cậu là chỉ chọn lấy ra một (vài) phần nào đó trong đám dữ liệu rồi vẽ tụi nó thôi. Thường thấy nhất là mấy phần khiến các cậu thấy lạc quan về tụi nó ấy, hoặc là vẽ nên bức tranh đối thủ của cậu đang ở trong tình trạng thảm hại thế nào.
Ví dụ nhe, chỉ vẽ biểu đồ của những tháng tăng trưởng cao chứ không vẽ cả toàn bộ năm ( vì bao gồm cả các tháng lỗ hoặc không tăng trưởng). Về kỹ thuật thì nó không có sai gì cả nhưng nó lại đang “dắt mũi” các cậu đó.
Thủ thuật này được gọi là improper extraction, nghĩa là chỉ lấy một mẩu trong toàn bộ dữ liệu để dựng nên biểu đồ thôi.
Improper extraction thường được dùng phổ biến trong mấy cái biểu đồ có trục thể hiện thời gian ấy. Chỉ cần biểu đồ thể hiện giống cái năm mà cậu đang nói tới thì người ta sẽ tin sái cổ luôn.
Cậu cũng có thể gọi thủ thuật này bằng tên một thủ thuật khác cũng gần giống như vậy omitting data. Cậu thử đoán nó là gì xem, nó có nghĩa là một số dữ liệu quan trọng sẽ bị loại bỏ khỏi biểu đồ vì một mục đích nào đó.
Cả hai cái improper extraction với omitting data là hay thứ cậu cực kì muốn né đấy.
Giờ hãy bắt đầu với một ví dụ của improper extraction nhé, bởi vì mình không nghĩ mình cần cho cậu thấy mấy cái ví dụ của omitting data đâu. Mình gặp khó khăn trong việc tìm ví dụ thực tế của đám ấy. Tại sao ư? Vì đâu có ai điên mà tự nhận mình bỏ bớt dữ liệu quan trọng ra làm gì đâu!
Nhưng mình tìm được mấy cái ví dụ hay hay này của Tejvan Pettinger về việc người ta có thể chọn ra phần nào đó của dữ liệu để thuyết phục hay lừa phỉnh các cậu.
Trong biểu đồ thứ nhất dưới này, người đọc có thể dễ dàng bị “dắt mũi” để nghĩ rằng UK chưa bao giờ mắc nợ công nhiều tới dữ vậy. Điều này thì có thể giúp tiếp tay cho ông chính trị gia nào đó đang ra sức kêu gọi thông qua mấy cái biện pháp giảm nợ chán chết.

Ê mà khoan chờ đã nha, khi mà cậu nhìn vào một cái biểu đồ đầy đủ các giai đoạn hơn, cậu sẽ thấy khi mang ra so sánh, số nợ công trong giai đoạn trên là thấp đấy.

Mấy kẻ tạo ra cái biểu đồ hư cấu này chỉ đơn giản chọn ra thời điểm lúc số nợ thấp và tạo ra ảo tưởng sai lầm là nó vọt lên tới mức này từ 0%. Bọn chúng cũng “sắp xếp” lại biểu đồ với một đống điểm được thêm vào vô tội vạ nhằm tạo ra cảm giác như là dữ liệu được vẽ trong đó nhiều lắm, trong khi thì thật ra chỉ có 10 năm thôi!
Đến đây nếu cậu còn muốn tìm hiểu thêm về cái improper extraction này ấy, thì cậu không cần nhìn đâu xa hết đâu, mà nó nằm ở ngay trong thị trường chứng khoán luôn.
Có hàng ngàn điểm mà người phân tích chứng khoán phải tìm hiểu trước khi họ thực hiện giao dịch hay khuyên người mua khác. Cho nên sẽ có nhiều điều họ phải loại bỏ đi để khiến người khác nhìn thấy tình trạng thị trường tốt hơn hay tệ đi.
Nhưng mình nghĩ thứ sẽ dụ khị cậu rất dễ dàng là giá cổ phiếu. Ví dụ nhé, cậu hãy nhìn vào biểu đồ bên dưới, nó cho thấy giá cổ phiếu của Twitter đang trong lúc được giá quá mà nhỉ.

Nếu mà mình là mấy tay nghiệp dư, khi nhìn vào thì mình sẽ nghĩ chắc là họ đang tiến triển tốt lắm đây.
Nhưng mình đã lầm...
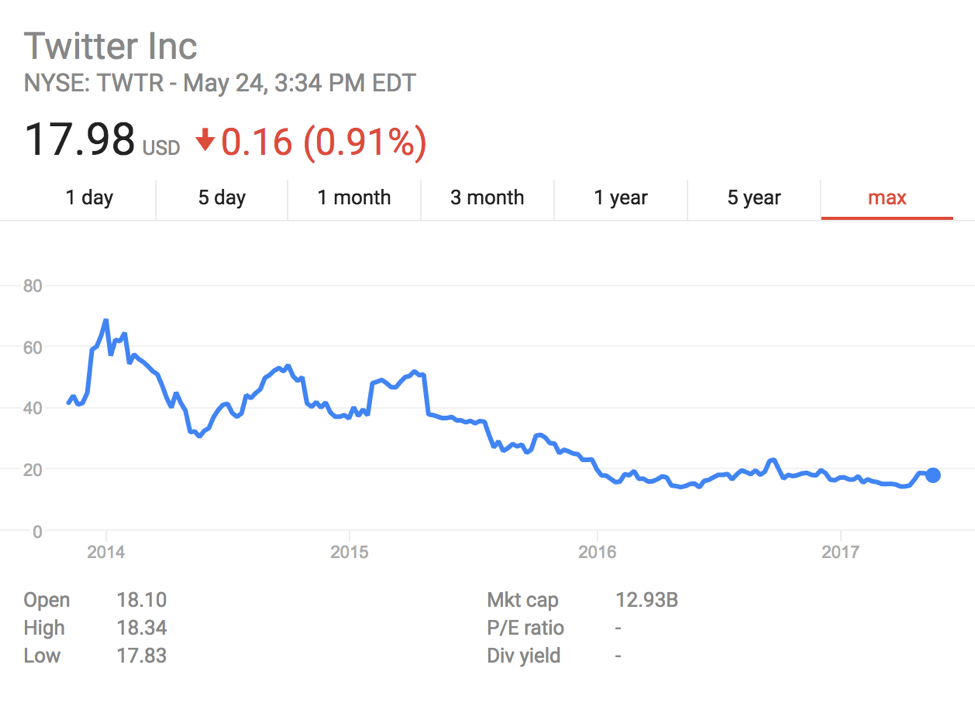
Họ đang trên đà tụt dốc mấy năm nay rồi, và sự tăng trưởng mà chúng ta thấy trong hình đầu tiên chỉ là một đốm sáng nhỏ nhoi trong chuỗi ngày tăm tối ấy mà thôi.
Và kiểu lừa bịp này có thể dùng để điều chỉnh bất kỳ dữ liệu nào chỉ để nhằm đạt được mục đích của cậu.
Như ở cái ví dụ này đây, nó đang cố thuyết phục mọi người tin rằng biến đổi khí hậu không hơn gì là một sự kiện hư cấu:

Ờ thường vì bởi đa số người ta đâu có chịu tìm hiểu kỹ dữ liệu gốc đâu mà mấy cái biểu đồ bịa đặt thế này đã làm họ thỏa mãn "cơn khát sự thật" rồi. Hoặc là họ nghĩ làm mấy cái biểu đồ hư cấu đăng lên Internet thế này thì cũng có lợi lộc gì đâu chứ!
Tổng kết
Trong phần này các bạn đã tìm hiểu thêm các thủ thuật khác để dựng nên một "biểu đồ lừa dối" bên cạnh một thủ thuật ở phần một. Sau đây là một số điểm mà mình nghĩ cần lưu ý lại:
a) Thuật ngữ "Omitting Baselines" là do tác giả trong bài sử dụng để phân chia rõ ràng hơn, và nếu các bạn muốn tìm hiểu thêm thì có thể tìm với cụm "Truncated graph" sẽ cho ra kết quả chính xác hơn. Và thủ thuật này thường được áp dụng trên trục tung (hoặc nó sẽ thành trục hoành nếu biểu đồ nằm ngang) trong những biểu đồ cột (Bar graph).
b) Thủ thuật Axis Changing trong phần hai với theo mình tìm hiểu thì sẽ được dùng nhiều nhất đối với biểu đồ đường (Line graph).
c) Có thể một vài bạn sẽ nhầm lẫn hai thủ thuật trong phần Cherry Picking Data là Improper extraction và Omitting data vì chúng gần giống nhau, nhưng chúng lại có điểm khác biệt. Bạn có thể hiểu thế này, Improper extraction thường dùng trong trường hợp biểu đồ chỉ thể hiện một phần bị cắt ra chứ không phải toàn bộ quá trình (thời gian). Còn Omitting data thì bạn vẫn có thể thấy quá trình thời gian trên cái biểu đồ ấy đầy đủ hết, không thiếu quãng nào, nhưng có một số thông tin đã bị loại bỏ một cách khéo léo.
d) Ngoài ra, đây là một video của Ted mà mình nghĩ sẽ thể hiện trực quan hơn những khái niệm trong bài (Link)
(Còn tiếp...)
Nguồn: Ryan McCready (Venngage.com)
Lời người dịch:
Bài lần này là của cùng một người dịch nhưng các bạn có thể thấy hai giọng văn khác nhau. Ở phần một, mình dịch theo kiểu "nghiêm túc" hơn và bám sát vào bản gốc hơn nhưng sau khi đọc lại mình thấy có một số chỗ có thể gây khó hiểu. Nên phần này mình đổi cách dịch theo mình là sẽ dễ xem hơn. (Hoặc đơn giản là các bạn hiểu do mình thích vậy cũng được :)) )
Mình mong sẽ nhận được góp ý nếu mọi người thấy sai sót hay muốn góp ý điều gì.

levent
@levent
Phát triển bản thân
/phat-trien-ban-than
Bài viết nổi bật khác
- Hot nhất
- Mới nhất