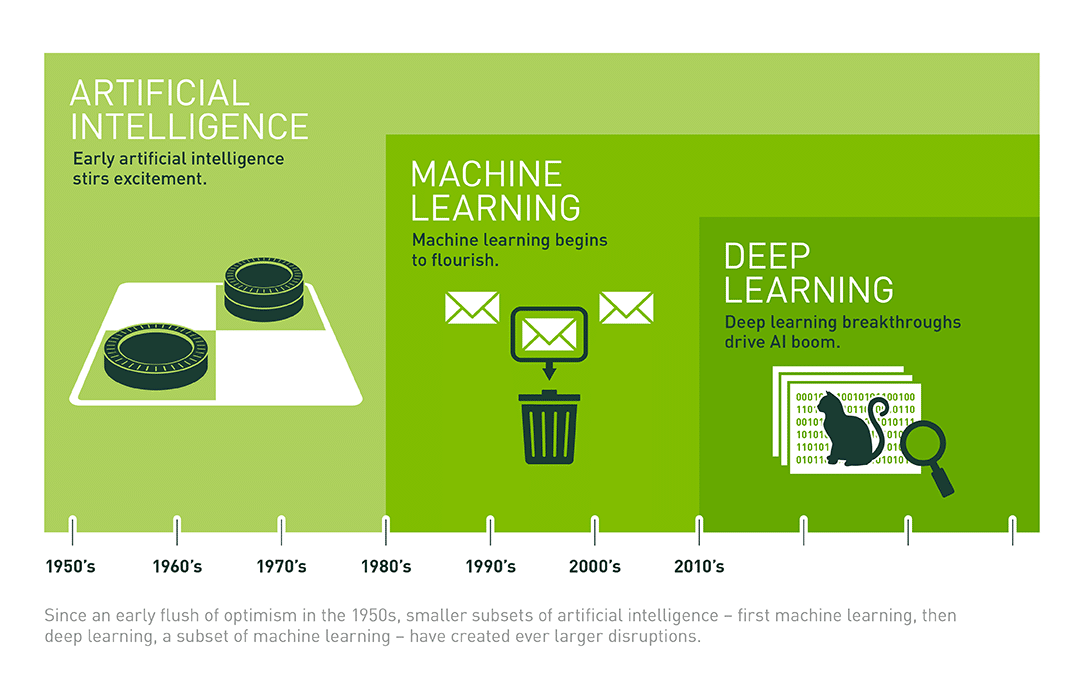
Lịch sử thế giới đã trải qua 3 cuộc Cách mạng công nghiệp. Lần thứ nhất với cơ khí hóa máy chạy bằng thủy lực và động cơ hơi nước, lần thứ 2 với năng lượng điện và dây chuyền sản xuất hàng loạt, lần thứ 3 với kỷ nguyên máy tính tự động hóa. Con người đang đi trên cuộc cách mạng công nghiệp lần thứ 4, mà nổi lên trong đó là Trí tuệ nhân tạo (Artificial intelligence - AI). Ta có thể thấy trí tuệ nhân tạo dường như len lỏi khắp nơi trong cuộc sống của ta: trợ lí ảo Siri của Apple hay Cortana của Microsoft, hệ thống lọc email spam của Gmail, tự động gợi ý bài hát của Spotify,...
Trí tuệ nhân tạo thường được hiểu cơ bản là máy móc bắt chước các chức năng nhận thức của con người, chẳng hạn như "học" và "giải quyết vấn đề", cách cư xử, sự học hỏi và khả năng thích ứng thông minh của máy móc.
Trí tuệ nhân tạo đã được nhắc đến từ rất lâu, trong những câu chuyện cổ tích huyền bí xưa, như những người máy bằng vàng của thần Hephaestus hay người khổng lồ Talos bằng đồng canh giữ đảo Crete trong thần thoại Hi Lạp chẳng hạn. Người khổng lồ Talos (Nguồn)
AI cũng được nêu lên vào thế kỉ XIX thông qua các tiểu thuyết, trong đó nổi tiếng nhất có lẽ là Frankenstein. Vào thời bấy giờ, người ta thường nhắc đến AI chủ yếu về các vấn đề của đạo đức:
Nếu một người máy có được tạo ra và có trí thông minh thì liệu nó cũng có thể cảm xúc? Giả sử nó có thể cảm xúc được, vậy nó có thể có được những quyền như con người hay không?
Đến thế kỉ XX, trong bài viết Máy tính và trí tuệ xuất bản năm 1950, nhà khoa học máy tính người Anh Alan Turing đã bắt đầu bằng một câu hỏi: "Máy tính có thể suy nghĩ không?"
Để trả lời câu hỏi này, ông đã đưa ra khái niệm “phép thử Turing”. Phép thử được thực hiện dưới dạng một trò chơi. Theo đó, có ba đối tượng tham gia trò chơi (gồm hai người và một máy tính). Một người (người kiểm tra) ngồi tách biệt với hai đối tượng còn lại. Người này đặt các câu hỏi và nhận các câu trả lời từ người kia và máy tính. Cuối cùng, nếu người kiểm tra không phân biệt được câu trả lời nào là của người, câu trả lời nào là của máy tính thì lúc đó có thể nói máy tính đã có khả năng "suy nghĩ" giống như người.
Turing tin rằng câu hỏi này hoàn toàn có thể trả lời. Trong phần còn lại của bài báo, Turing đã chống lại những ý kiến phản đối về việc "máy tính có thể suy nghĩ".
Phép thử này cũng có những nhược điểm. Nó dựa trên giả thiết rằng người ta có thể đánh giá tính "thông minh" của máy tính bằng cách so sánh hành vi của nó với hành vi của con người. Tuy nhiên, kết quả của thử nghiệm có thể dễ dàng bị chi phối không phải bởi tính thông minh của máy tính, mà vì thái độ của người hỏi. Mặc dù phép thử Turing không hoàn hảo, nhưng nó thực sự đã tạo nên một cú nổ lớn về AI thời bấy giờ, mà giá trị của phép thử này đến bây giờ vẫn còn được sử dụng rộng rãi.
Vào mùa hè 1956, tại một cuộc hội nghị ở Đại học Dartmouth College, lĩnh vực nghiên cứu về Trí tuệ nhân tạo đã chính thức được thành lập . Những người tham dự về sau trở thành những nhà lãnh đạo cho lĩnh vực này, nổi bật là John McArthy, Marvin Minsky, Allen Newell và Herbert Simon.
Trong khoảng những thập niên 60-70, đã có thêm một vài dự án về AI như chương trình ANALOGY của Thomas Evan, Project MAC giải quyết các vấn đề về Đại số (algebra word problem), ELIZA của Joseph Weizenbaum trong việc giao tiếp giữa con người và máy tính (đây chính là tiền thân của các ứng dụng chat bot nhan nhản ngày nay).
Dù đạt được nhiều kết quả khá khả quan, nhưng vào thời bấy giờ, do hạn chế về giới hạn khả năng của trang thiết bị nên việc tổng quát hóa những thành công bước đầu đạt được trong các hệ chương trình AI đã xây dựng là rất khó. (Đã từng có một giai đoạn gọi là AI Winter).
Đến 10 tháng 2 năm 1996, sau chiến thắng trận đầu tiên giữa kiện tướng cờ vua Garry Kasparov với máy tính DeepBlue của IBM, AI đã thực sự có một cú nhảy vọt mạnh mẽ so với khoảng thời gian trước đó.
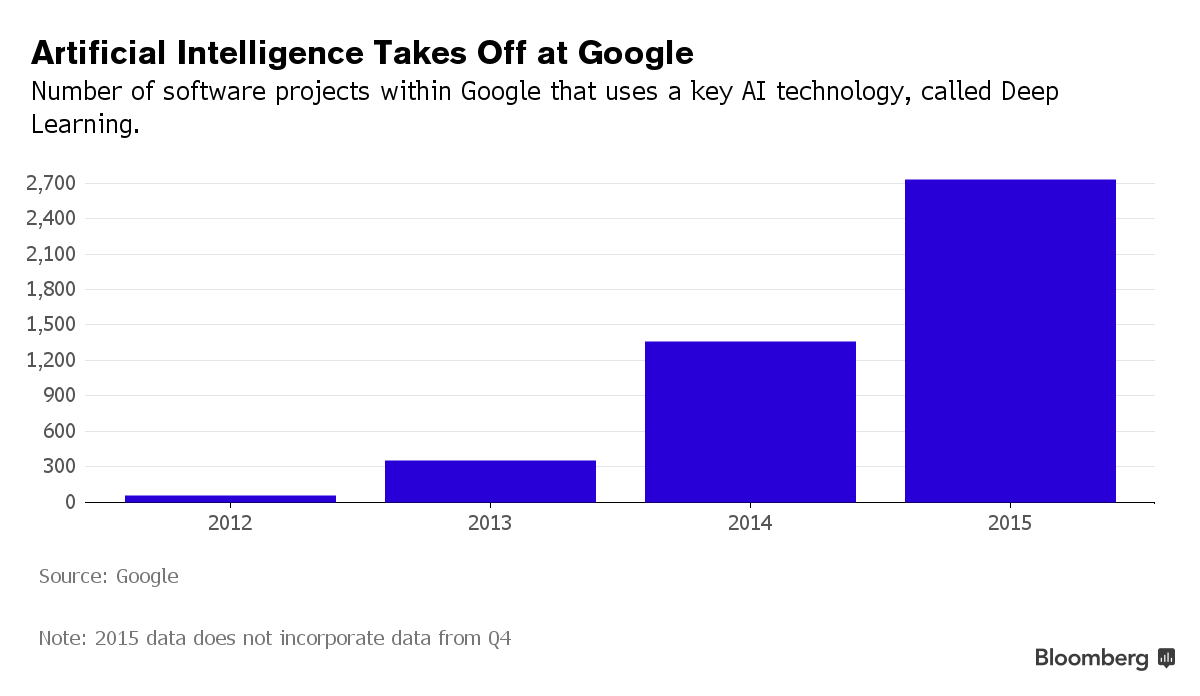
Năm 2015 được xem là một bước ngoặt mang tính chất lịch sử của AI, với số lượng dự án phần mềm sử dụng AI trong Google tăng từ "sử dụng lẻ tẻ" trong năm 2012 lên tới hơn 2.700 dự án.
Trên đây chỉ là sơ lược về nguồn gốc của AI, infographic sau có thể cho ta rõ nét hơn về nguồn gốc, hiện tại và cả tương lai về AI:
Các hướng tiếp cận chính của AI
Các nhà nghiên cứu thường phân thành các hướng tiếp cận thành 2 hướng là Thể loại và Mục đích.
Thể loại tiếp cận:
Hành động như người (acting humanly)
Suy nghĩ như người (thinking humanly)
Suy nghĩ hợp lý (thinking rationally)
Hành động hợp lý (acting rationally)
Mục đích tiếp cận:
Suy luận (Automated reasoning)
Biểu diễn tri thức (Knowledge representation)
Lập kế hoạch và lên lịch tự động (Automated planning and scheduling)
Xử lí ngôn ngữ tự nhiên (Natural language processing)
Tri giác (Machine perception)
Học hỏi (Machine learning)
Khoa học nhận thức (Cognitive science) là một trong những xu hướng tiếp cận khác trong lĩnh vực này, đây là một ngành có yêu cầu kiến thức rất rộng lớn, vì ta phải hiểu được con người suy nghĩ như thế nào thì mới áp dụng được cho máy tính. Cognitive science bao gồm tâm lý học, thần kinh học, ngôn ngữ học, triết học, trí tuệ nhân tạo, nhân loại học, và sinh học.
Nguồn: Wikipedia
Nói về Machine learning
Định nghĩa
Machine learning is the subfield of computer science that “gives computers the ability to learn without being explicitly programmed” - Wikipedia
Có thể hiểu đơn giản rằng Machine Learning là một lĩnh vực nhỏ của Khoa học máy tính (1 trong 6 mục đích tiếp cận như trên), nó có khả năng tự học hỏi dựa trên dữ liệu đưa vào mà không cần phải được lập trình cụ thể.
Một trong những ví dụ cơ bản nhất của Machine Learning đó chính là việc phân loại email, mỗi ngày ta nhận được hàng trăm email, nhưng số lượng email rác không nhỏ. Làm cách nào để viết một chương trình lọc mail khi thư gửi tới email của mình và quyết định tống chúng vào hòm spam hoặc hộp thư đến?
Gmail sẽ tự động kiểm tra thư và xác định xem đó có phải là email spam hay không và chuyển nó vào thư mục thích hợp.
Việc đầu tiên mà phần lớn mọi người thường nghĩ, đó là ta sẽ lấy một vài mail ví dụ rồi kiểm tra, xem cái nào là spam hoặc không. Tiếp theo, vì số lượng mail thường là rất lớn và không thể lọc thủ công được, ta sẽ trừu tượng hóa các mẫu mail ví dụ đó để dự đoán cho các mail tiếp theo. Tuy nhiên, đôi khi vẫn có các trường hợp bị sai sót, ta sẽ tiếp tục thu thập dữ liệu từ những lần kiểm tra trước và tạo ra các mẫu trừu tượng hóa mới hơn, tốt hơn và ít lỗi hơn.
Đó chính xác là những gì mà Machine Learning đã thực hiện. Như ta thấy, Machine Learning có thể tóm tắt bằng 2 từ "dự đoán".
Học có giám sát là phương thức học phổ biến nhất trong Machine Learning. Phương thức học này cũng chính là ví dụ cho định nghĩa của Machine Learning ở trên: ta đưa dữ liệu vào (input) gồm nhiều cặp dữ liệu, mỗi cặp gồm 2 thứ là data - label (dữ liệu - nhãn), ta gọi các cặp này là dữ liệu huấn luyện (training data),Từ tập traing data này, khi có một dữ liệu (data) mới, máy tính sẽ dự đoán được nhãn (label) tương ứng với nó.
Để dễ hiểu hơn, ta có thể giải thích theo cách toán học như sau, chẳng hạn ta có một tập X (dữ liệu) và một tập Y (nhãn):
Từ các cặp dữ liệu (x, y) tương ứng trên, ta sẽ tạo một hàm số ánh xạ mỗi phần tử của tập X sang một phần tử của tập Y tương đương.
Sau khi training đã hoàn tất, từ một dữ liệu x mới, ta có thể tính ra được nhãn y tương đương với nó.
Ví dụ:
Ta cần nhận diện một lượng lớn các loại trái cây có phải là chuối hay không bằng chiều dài của từng loại. Đầu tiên, ta cần đưa một lượng dữ liệu vào để training, chẳng hạn như dưới đây:
Sau khi đã training xong, ta sẽ thử đưa một vài mẫu data, máy tính sẽ phân tích cho thấy kết quả này có xấp xỉ với chiều dài của chuối (từ những dữ liệu đã được học)hay không, từ đó đưa ra kết quả dự đoán. Chẳng hạn:
Đây là chuối.
Đây không phải là chuối.
Đây cũng chính là tính 2 mặt của cách học này. Với nhược điểm, vì không phải khi nào thì label cũng tương xứng với data, chẳng hạn như ví dụ trên, không phải chuối nào cũng dài hơn 10cm cả. Tuy nhiên, ưu điểm của nó cũng chính vì một khi đã thu được một bộ data - label tin cậy thì việc training trở nên dễ dàng đưa ra dự đoán cũng chính xác hơn.
Học không giám sát (Unsupervised Learning)
Thuật toán này cũng gần giống như Supervised Learning, nhưng chúng ta không biết được nhãn mà chỉ có dữ liệu đầu vào. Tức là ta chỉ có tập X (dữ liệu) chứ không có tập Y (nhãn).
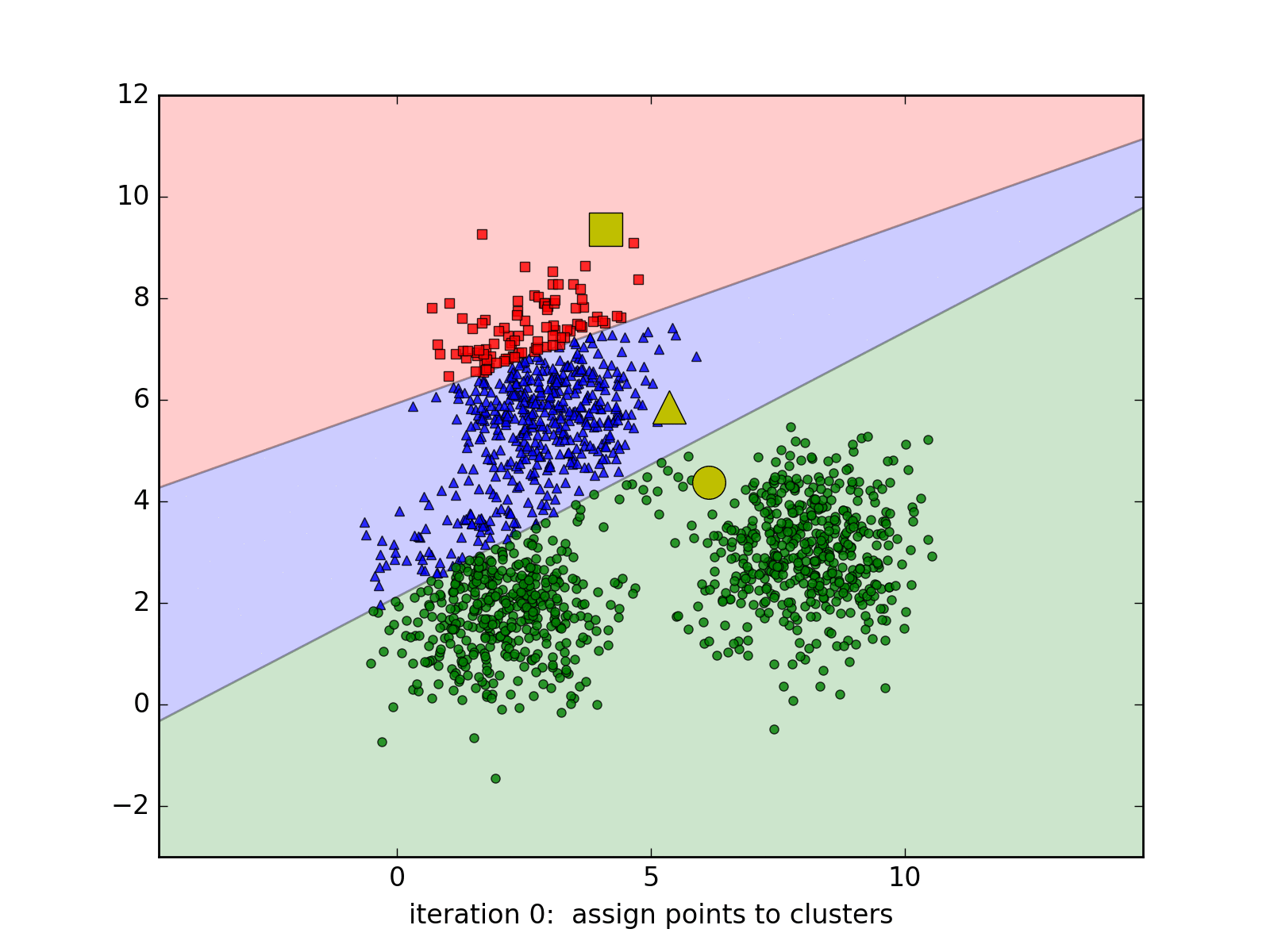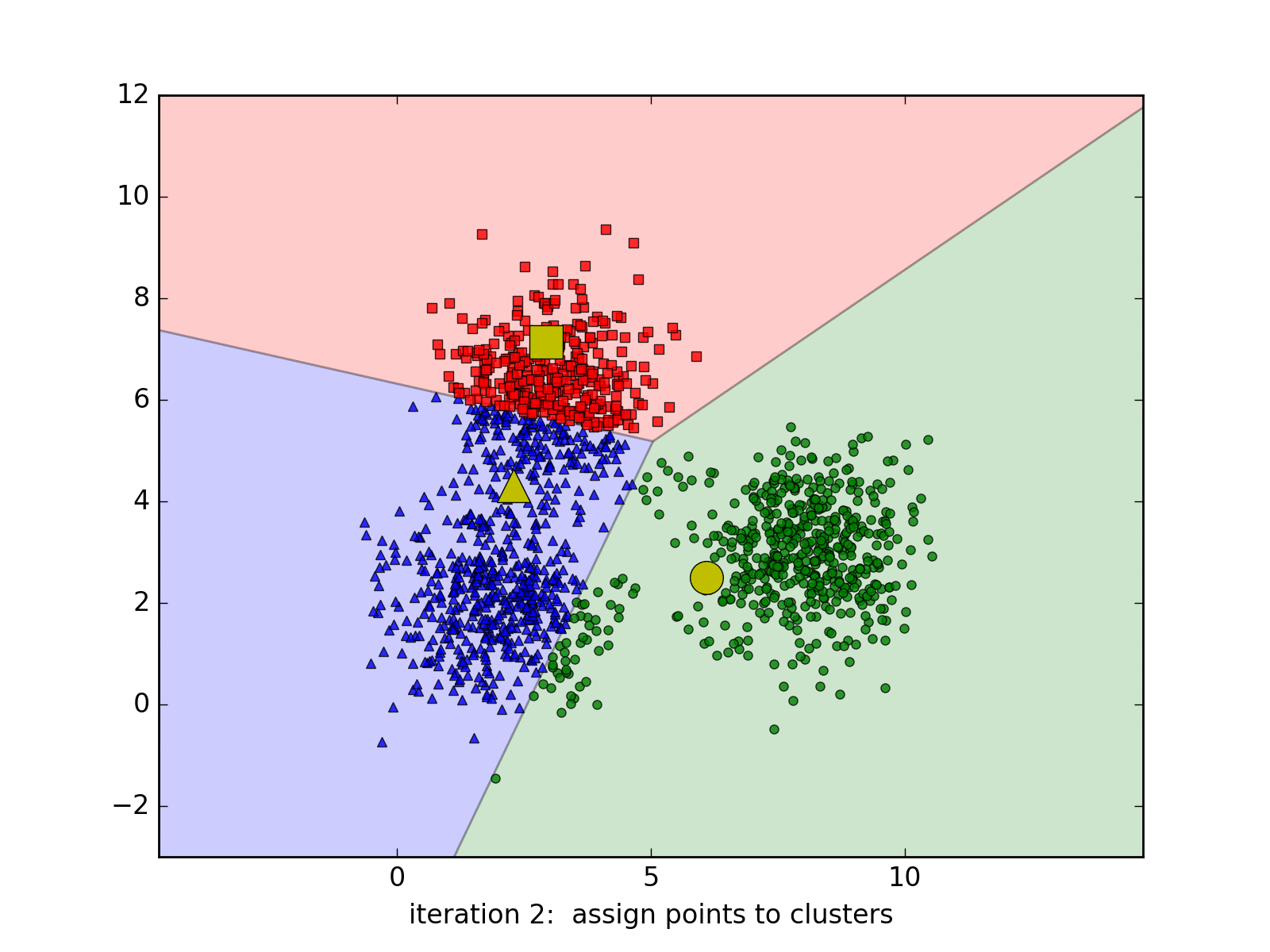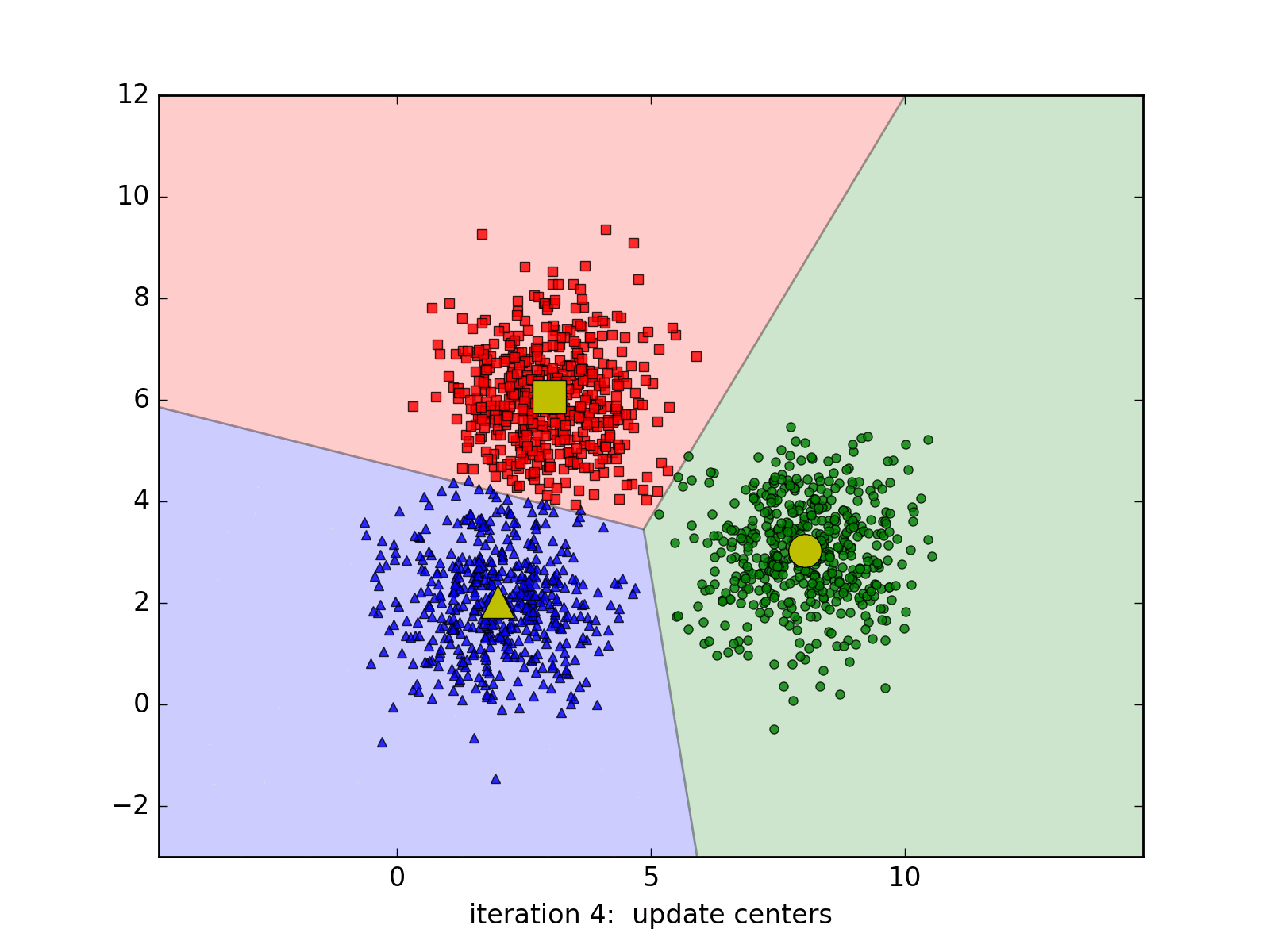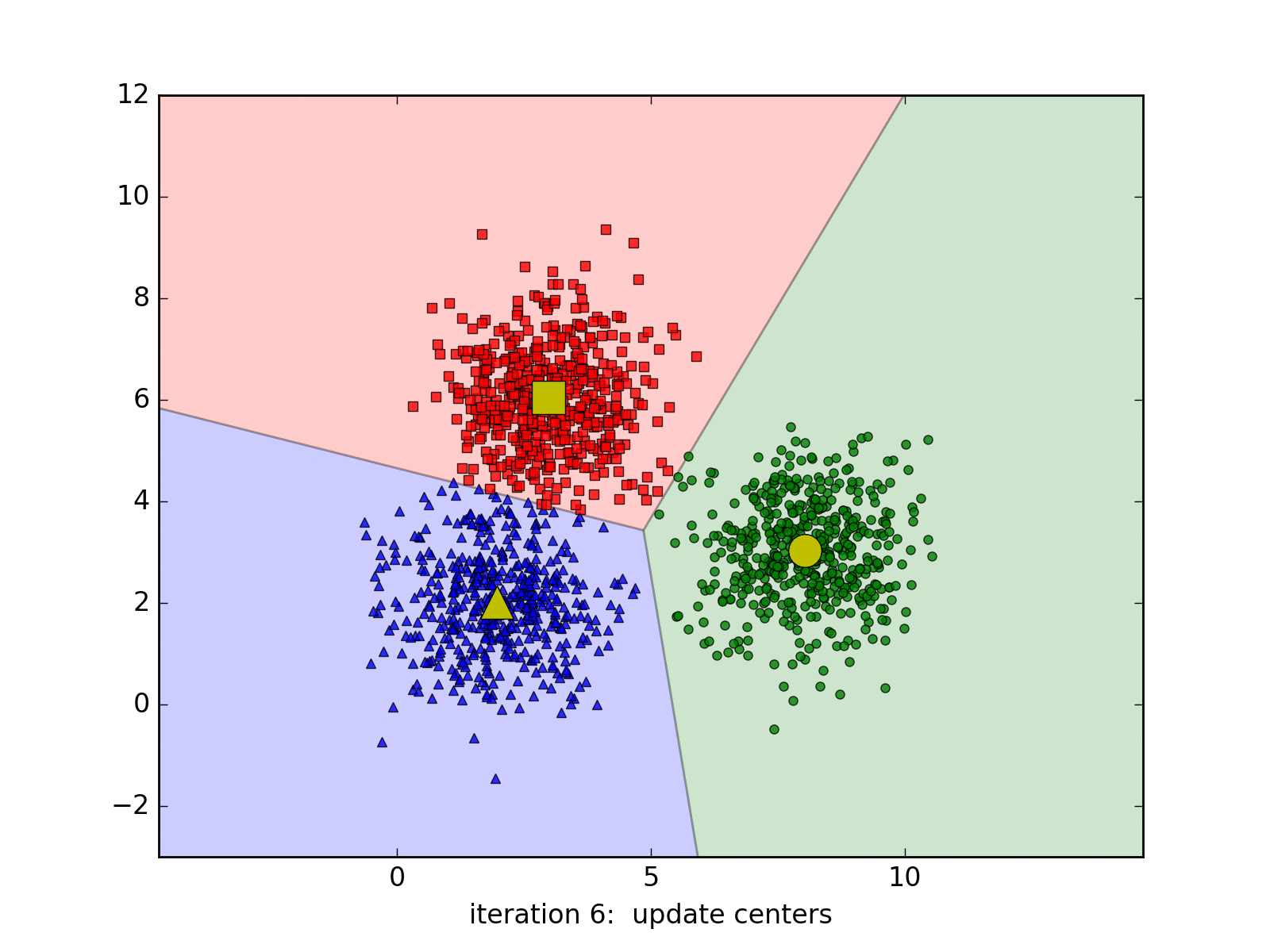
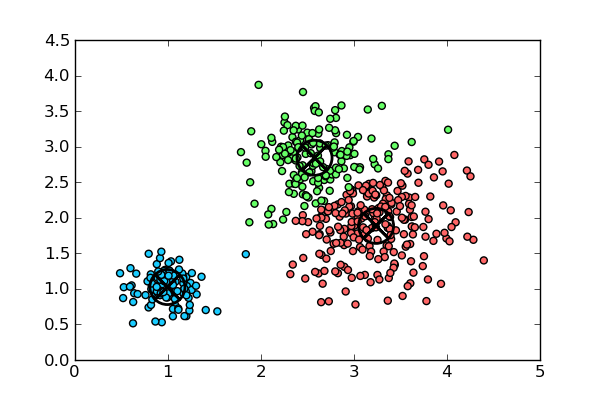
Các thuật toán Unsupervised Learning sẽ dựa vào cấu trúc của dữ liệu để thực hiện các công việc, phổ biến nhất là phân nhóm (clustering). Trong dạng bài toán này, tập dữ liệu X sẽ được phân nhỏ ra và nhóm lại theo sự liên quan dữ liệu.
Mô tả quá trình làm việc của thuật toán K-Means Clustering. (Nguồn)
Chẳng hạn ta có bài toán sau: Ta có dữ liệu về độ dài và cân nặng của 1000 trái cây gồm 3 loại hoa quả, nhưng lại bị lẫn lộn với nhau, câu hỏi đặt ra là, làm sao để có thể phân loại được số hoa quả này?
Để giải quyết bài toán này, đầu tiên ta xem dữ liệu của số hoa quả trên là tập dữ liệu X:
Bây giờ ta sẽ tiến hành phân nhóm (clustering) thành các cụm (cluster) dựa trên sự tương đồng giữa dữ liệu vào (chiều dài, cân nặng) của hoa quả. Giả sử sau khi phân nhóm xong ta thu được biểu đồ sau:
Lúc này, ta chỉ cần dựa vào biểu đồ, lựa chọn ra một số nhỏ trong từng nhóm để phân xem nó thuộc loại nào. Phần việc này mặc dù cần sự can thiệp thủ công, nhưng nó vẫn tiết kiệm được rất lớn thời gian.
Ưu điểm thì như ta đã thấy, nó tiết kiệm khá nhiều thời gian, cũng như nhóm các dữ liệu liên quan lại với nhau khá trực quan. Tuy nhiên, nhược điểm thì nó không quá chính xác trong nhiều trường hợp, chẳng hạn như bị phân tán như thế này:
Các bạn có thể vào trang web này để hình dung cách hoạt động của K-Means Clustering - một thuật toán phổ biến và đơn giản nhất để giải quyết bài toán Clustering.
Học bán giám sát (Semi-Supervised Learning)
Giống như tên của nó, các bài toán khi ta có một lượng dữ liệu nhưng chỉ một phần trong chúng được gán nhãn thì gọi là Semi-Supervised Learning.
Trong thực tế thì nhóm này khá là phổ biến, một trong những ứng dụng phổ biến của phương thức học này là Speech Analysis - Phân tích giọng nói. Để phân tích giọng nói rồi dán nhãn lên thực sự cần rất nhiều kiến thức chuyên sâu về âm thanh, môi trường,..., nhìn chung khá tốn kém. Trong khi đó, ta có thể thu thập một ít dữ liệu được dán nhãn, sau đó áp dụng Semi-Supervised Learning với số lượng lớn dữ liệu chưa dán nhãn khác, điều này sẽ giúp giảm thiểu chi phí và thời gian khá nhiều so với cách phân tích truyền thống.
Reinforcement Learning là các bài toán giúp cho một hệ thống tự động xác định hành vi dựa trên hoàn cảnh để đạt được lợi ích cao nhất. Những thuật toán Reinforcement Learning giống như cách mà não loài chuột phản ứng với hình phạt và phần thưởng vậy. Nó thường có xu hướng cố gắng hành động thật nhiều để đạt được phần thưởng cao nhất.
Các thuật toán Reinforcement Learning có thể bắt đầu làm việc mà không cần bất kỳ dữ liệu ban đầu. Chúng có thể thu thập dữ liệu khi bắt đầu chạy và học thông qua thử và sai. Về cơ bản thì các thuật toán này thích hợp cho các hệ thống tự động không cần sự hướng dẫn của con người, chẳng hạn như lò sưởi, điều hòa, robot,....
Cơ chế hoạt động của Reinforcement Learning. (Nguồn)
Một trong những ứng dụng nổi tiếng đó là AlphaGo - chương trình chơi cờ vây do Google DeepMind phát triển. Vào tháng 3 năm 2016, nó đã đánh bại Lee Sedol - đương kim vô địch thế giới trong ba trên năm trận. Cờ vây có xuất phát từ Trung Quốc, là một môn cờ có độ phức tạp vô cùng lớn, nó có tổng số nước lên tới 10^761 (cờ vua có tổng số là 10^120 nước đi). Vì vậy, ta không thể chọn thuật toán vét cạn vì khó có một máy tính nào có thể làm nổi điều này, mà máy phải chọn ra 1 nước đi tối ưu nhất trong số hàng tỉ tỉ lựa chọn khác nhau.
AlphaGo & Lee Sedol. (Nguồn)AlphaGo bao gồm các thuật toán thuộc cả Reinforcement Learning lẫn Supervised Learning. Với Supervised Learning, dữ liệu từ các ván cờ do con người chơi được đưa vào để huấn luyện. Sau khi học xong các ván cờ của con người, AlphaGo tự chơi với chính nó với hàng triệu ván chơi để tìm ra các nước đi mới tối ưu hơn không chỉ với mục đích sánh ngang, mà phải chiến thắng được con người.
Deep Learning là gì?
Deep Learning là một phần nhỏ trong Machine Learning, khi mà khả năng tính toán của các máy tính được tăng cao và sự bùng nổ của các ngành khoa học dữ liệu, Machine Learning đã tiến thêm một bước dài và một lĩnh vực mới được ra đời gọi là Deep Learning. Mối quan hệ giữa AI - Machine Learning - Deep Learning. (Nguồn)
Các mô hình Deep Learning hiện nay đều dựa trên mạng nơron nhân tạo - Artificial Neural Network.
Vậy Artificial Neural Network (ANN) là gì?
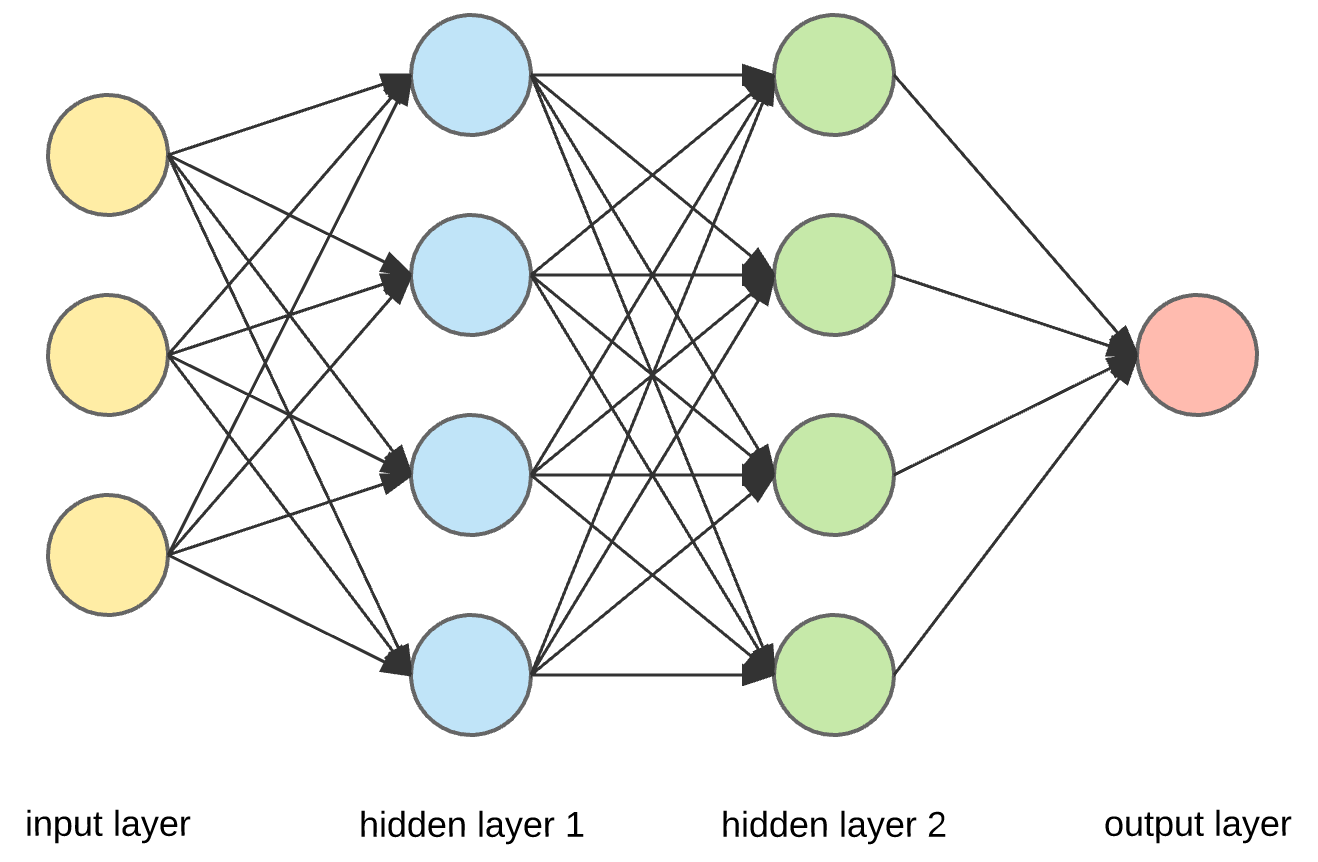
Kiến trúc tổng quan của ANN
Processing Elements (thành phần xử lí): Các thành phần xử lí của ANN gọi là neuron (mỗi neuron chính là 1 hàm số), mỗi neuron nhận các dữ liệu vào (input) xử lý chúng và cho ra một kết quả (output). Kết quả xử lý của một neuron có thể làm input cho các neuron khác
Kiến trúc chung của một ANN gồm 3 thành phần đó là Input Layer, Hidden Layer và Output Layer:
Trong đó, Hidden Layer gồm các neuron nhận dữ liệu input từ neuron ở layer trước đó rồi xử lí input này, sau đó tiến hành xuất dữ liệu ra (output) cho các lớp xử lý tiếp theo. Trong một ANN có thể có nhiều Hidden Layer:
Như vậy, ta có thể thấy rằng ANN có thể sử dụng Supervised hay Unsupervised Learning đều được.
Artificial Neural Network và Deep Learning có gì khác nhau?
Có thể hiểu Deep Learning chính là Neural Network với nhiều Hidden Layer. Một ANN cơ bản có thể có vài Hidden Layer, nhưng với Deep Learning, con số đó có thể lên đến hàng trăm, hàng ngàn hoặc hàng triệu layer.
Bước xử lí chiều dài thân, màu lông, đếm số chân chó,... nằm trên Hidden Layer.
Game Quick, Draw! của Google cũng được xây dựng bằng Deep Learning. Ban đầu, họ có một lượng dữ liệu để training cho ANN này. Sau đó, khi ta vẽ, game sẽ so sánh hình vẽ của ta với những ví dụ được vẽ bởi những người khác. Mặc dù người dùng có kỹ năng vẽ không tốt lắm thì Google vẫn nhận biết khá tốt những hình vẽ cơ bản như nhà, kính, bãi biển,....
và cả chuối chẳng hạn.
Vấn đề về truyền thông đối với AI
Để kết thúc bài này thì ta sẽ nói qua về truyền thông nói về AI, nhiều tờ báo cho rằng AI phát triển đến một mức nào đó sẽ thống trị con người như trong các bộ phim viễn tưởng Hollywood. Nhưng, sự thật là máy móc chỉ hỗ trợ khả năng sáng tạo của con người chứ bản thân chúng không hề có khả năng này, nó chỉ có thể làm theo yêu cầu của con người chứ không tự nghĩ ra nhu cầu dành riêng cho mình. Theo ý kiến cá nhân, thì việc AI thống trị con người trong tương lai, tiến hành tiêu diệt con người là điều bất khả thi. Mà những cuộc thảm sát hay diệt chủng thì đều từ con người ra cả mà.