

Spotify's Discover Weekly: Cách máy học tìm thấy những bài hát bạn sẽ yêu thích
Dịch nhanh bài Spotify’s Discover Weekly: How machine learning finds your new music của Sophia Ciocca Ngành khoa học đằng sau...


Dịch nhanh bài Spotify’s Discover Weekly: How machine learning finds your new music của Sophia Ciocca
Ngành khoa học đằng sau sự gợi ý âm nhạc cá nhân hóa (personalized music recommendations)
Hôm nay là thứ hai — cũng như những ngày thứ hai khác — hơn 100 triệu người dùng Spotify đã tìm thấy một playlist hoàn toàn mới đang chờ họ. Nó là một danh sách mix ngẫu nhiên các bản nhạc (custom mixtape) của 30 bài hát mà họ chưa từng nghe bao giờ trước đó nhưng chắc chắn sẽ thích. Điều này chính là Discover Weekly, và nó là một phép màu kì diệu.
Tôi là một fan bự của Spotify, đặc biệt là Discover Weekly. Vì sao ư? Vì nó (Discover Weekly) tạo cho tôi cảm giác được thấu hiểu. Nó biết gu âm nhạc cua tôi hơn bất ai trong cuộc đời tôi, và tôi cực kỳ hài lòng bởi cách mà Discover Weekly làm tôi thỏa mãn hàng tuần, với những bản nhạc mà tôi sẽ thích nhưng sẽ rất khó để tìm thấy hoặc chưa biết đến.
Cho những ai sống trong một bức tường cách âm với rock (who live under a musically soundproof rock), để tôi giới thiệu người bạn ảo tuyệt nhất của mình (my virtual best friend):
Có vẻ như, tôi không phải là người duy nhất bị ám ảnh bới Discover Weekly mà hầu hết người dùng đều phát cuồng vì nó. Điều này dẫn đến việc Spotify hoàn toàn thay đổi suy nghĩ nên tập trung vào Discover Weekly, đầu tư nhiều nguồn lực vào danh sách bài hát được xây dựng dựa trên thuật toán (algorithm-based playlists).
Từ khi Discover Weekly ra mắt vào 2015, tôi đã chết mê mệt để tìm cách nó hoạt động (I’ve been dying to know how it worked) (thêm một điều tôi là một fangirl của Spotify, vì thế thỉnh thoảng tôi sẽ giả vờ là tôi đang làm việc và tìm hiểu về sản phẩm của họ). Sau 3 tuần google điên cuồng (mad googling), tôi cảm thấy dễ chịu hơn khi cuối cùng cũng đã có được cái nhìn tổng quan đằng sau bức màn bí mật.
Cái nhìn tổng quan về lịch sử ngành công nghiệp âm nhạc trực tuyến (A brief history of online music curation)

Quay lại những năm 2000s, Songza đã khởi đầu the online music curation scene bằng cách sử dụng manual curation để tạo playlist cho người dùng. “Manual curation” nghĩa là một vài nhóm “chuyên gia về âm nhạc” (music experts) hoặc những người phụ trách khác (other curators) sẽ đặt những playlist cùng nhau bằng tay mà họ nghĩ là hay, sau đó người nghe sẽ nghe những playlist đã được sắp đặt đó. (Sau đó, Beats Music đã áp dụng chiến lược tương tự). Manual curation hoạt động tốt, nhưng nó quá thủ công và đơn giản, và vì thế nó không thể tính đến sắc thái gu âm nhạc của từng người nghe. (the nuance of each listener’s individual music taste.)
Giống như Songza, Pandora as also one of the original players in the music curation scene. Pandora đã khéo léo sử dụng một cách tiếp cận tiến bộ hơn, thay vì gắn tag thủ công các thuộc tính của một bài hát (manually tagging attributes). Điều này có nghĩa là một nhóm người sẽ nghe nhạc,chọn ra một loạt các từ để miêu tả cho từng bài, và gắn tag từng bài hát với những từ đó. Sau đó, Pandora’s code có thể lọc một cách đơn giản một vài tag nào đó để tạo ra những playlist có gu âm nhạc tương tự (similar-sounding music).
Cũng trong khoảng thời gian đó, a music intelligence agency từ MIT Media Lab tên là The Echo Nest ra đời, đã thay đổi hoàn toàn cách tiếp cận để cá nhân hóa âm nhạc (took a radically more advanced approach to personalized music). The Echo Nest sử dụng thuật toán để phân tích âm thanh và nội dung văn bản( used algorithms to analyze the audio and textual content of music), cho phép nó thể hiện sự nhận diện của âm nhạc (music identification), cá nhân hóa gợi ý (personalized recommendation), tạo playlist, và phân tích.
Cuối cùng, Last.fm đã có một cách tiếp cận hoàn toàn khác, cách mà vẫn tồn tại đến bây giờ và nó sử dụng một quy trình được gọi là bộ lọc kết hợp (collaborative filtering) để xác định âm nhạc mà người dùng có thể thích. Và còn nhiều hơn thế, tất cả chỉ trong một khoảnh khắc.
Vậy nếu đó là cách những dịch vụ của music curation khác gợi ý thì Spotify đã làm như thế nào với cỗ máy thần kỳ của họ (magic engine). Điều mà dường như tối ưu cho gu âm nhạc cho từng người dùng chính xác hơn bất kỳ một dịch vụ nào?
Spotify’s 3 Types of Recommendation Models
Thực ra, Spotify không sử dụng một mô hình gợi ý mang tính cách mạng đơn lẻ nào (a single revolutionary recommendation model), thay vào đó, họ kết hợp những chiến lực tốt nhất đã được sử dụng bởi các dịch vụ khác để tạo nên cỗ máy khám phá độc nhất vô nhị của mình (uniquely powerful Discovery engine).
Để tạo nên Discover Weekly, có 3 kiểu mô hình recommendation chính được Spotify áp dụng:
1. Collaborative Filtering models (kết hợp các bộ lọc) — vd: đây là cách mà Last.fm đã dùng ban đầu), mô hình này hoạt động bằng cách phân tích hành vi của bạn và của những người khác.
2. Natural Language Processing (NLP) models (Xử lý ngôn ngữ tự nhiên), mô hình này hoạt động bằng cách phân tích text (văn bản)
3. Audio models, hoạt động bằng cách phân tích file âm thanh thô (raw audio tracks themselves.)
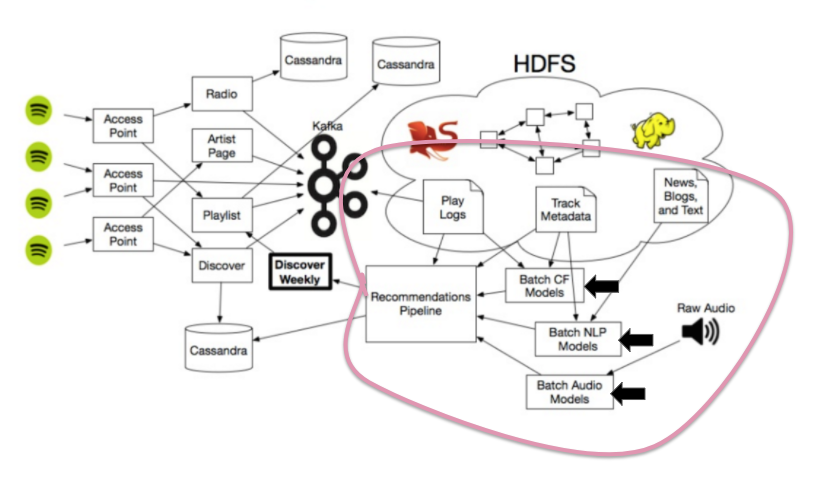
Image credit: Chris Johnson, Spotify
Hãy cùng nhìn sâu vào cách từng mô hình recommendation hoạt động.
Recommendation Model #1: Collaborative Filtering

Đầu tiên, một vài thông tin cơ bản: khi nhiều người nghe từ “collaborative filtering”, họ sẽ nghĩ đến Netflix, một trong những công ty đầu tiên sử dụng collaborative filtering để tăng hiệu quả của recommendation, sử dụng users’s star-based movie ratings để tạo nên những hiểu biết của Netflix về những bộ phim được recommend cho những người dùng có sở thích “tương tự” nhau (other “similar” users)
Sau khi Netflix áp dụng thành công, collaborative filtering nhanh chóng phổ biến, và bây giờ nó là một trong những phương pháp đáng xem xét để bắt đầu cho những ai muốn tạo nên một recommendation model.
Không giống như Netfilx, Spotify không có những điểm khi người dùng đánh giá âm nhạc của họ (Spotify doesn’t have those stars uiwth which users rate their music). Thay vào đó, dữ liệu của Spotify là những đánh giá tiềm ẩn (implicit feedback) — đặc biệt, số lượt stream (the stream counts) của những bài hát chúng ta nghe, cũng như những dữ liệu streaming bổ sung (additional streaming data), bao gồm bất kỳ điều gì mà người dùng lưu bài bát vào playlist của họ, hoặc ghé thăm trang của nghệ sĩ sau khi nghe.
Nhưng collaborative filtering là gì, và nó hoạt động như thế nào? Here’s a high-level rundown, được đóng gói trong một đoạn hội thoại nhanh:

Điều gì đang xảy ra ở đây? Mỗi người trong ảnh đều có một vài bài hát yêu thích. Anh chàng bên trái thích tracks P, Q, R và S; anh chàng bên phải thì thích tracks Q, R, S và T.
Collaborative filtering sử dử dụng những gì dữ liệu thể hiện,
“Hmm. Cả 2 cậu đều thích 3 tracks giống nhau — Q, R và S — vì thế các cậu nhiều khả năng là những users giống nhau (similar users). Vì thế, mỗi người các cậu có thể sẽ thích bài còn lại mà người kia đang nghe, bài mà các cậu chưa bao giờ nghe”.
Đấy là lý do vì sao gợi ý cho cậu bên phải nghe thử track P, và cậu bên trái nghe thử track T. Đơn giản phải không?
Nhưng làm thế nào để Spotify thực sự sử dụng concept này để áp dụng cho việc tính toán hàng triệu suggest cho người dùng dựa trên hàng triệu bài hát mà người dùng khác thích nghe?
…. Một ma trận toán học, được xử lý bằng Python libraries!
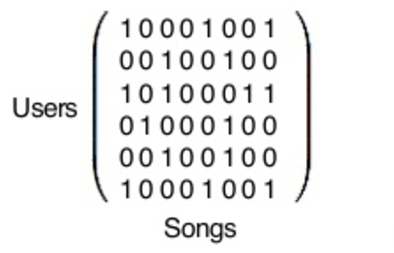
Thực tế, ma trận bạn đang nhìn thấy ở đây là gigantic. Mỗi cột đại diện cho một trong 140 triệu người dùng của Spotify (nếu bạn sử dụng Spotify, bạn là một cột trong ma trận này) và mỗi hàng đại diện cho 1 trong 30 triệu bài hát trong cơ sở dữ liệu của Spotify (Spotify’s database).
Sau đó, the Python library sẽ thực hiện một công thức phân loại phức tạp dài dằng dặc: (this long, complicated matrix factorization formula)
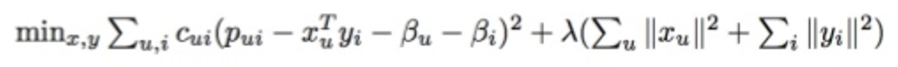
Some complicated math…
Khi công thức trên chạy xong, ta sẽ kết thức với 2 hướng của vectors, đại diện ở đây là X và Y. X là vector người dùng, đại diện cho gu âm nhạc của một người dùng đơn lẻ (one single user’s taste), và Y là vector bài hát, đại diện cho một hồ sơ của một bài hát đơn lẻ (one single song’s profile).
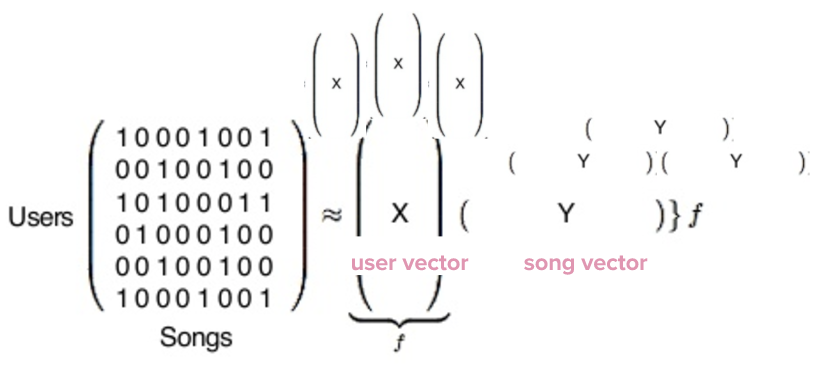
Bây giờ, chúng ta có 140 triệu user vectors — mỗi vector đại diện cho một user — và 30 triệu song vectors. Nội dung thực tế của mỗi loại vectors chỉ là một đống con số mà về bản chất, chẳng có ý nghĩa gì với chúng (những con số), nhưng những con số này rất hữu dụng khi dùng để so sánh.
Để tìm những người dùng có gu âm nhạc tương tự với tôi, collaborative filtering so sánh vector của tôi với tất cả những vector của người dùng khác, và cuối cùng sẽ tìm được người dùng giống tôi nhất (về gu âm nhạc). Điều tương tự cũng xảy ra với vector Y, những bài hát — bạn có thể so sách một vector bài hát (a song’s vector) với tất cả những vector bài hát khác, và tìm được những bài hát giống với bài mà bạn đang tìm.
Collaborative filtering đã thực hiện rất tốt nhiệm vụ của mình, nhưng Spotify biết rằng họ có thể làm tốt hơn bằng cách thêm một cỗ máy khác. Đó là NLP.
Recommendation Model #2: Natural Language Processing (NLP)
Model recommendation thứ 2 được Spotify sử dụng là Natural Language Processing (NLP) models. Nguồn dữ liệu của model này, như cái tên tự nó đã nói lên, là regular ol’words — track metadata, news articles, blogs, và một vài văn bản khác trên internet.

Cơ chế chính xác đằng sau NLP thì đã vượt ra ngoài phạm vi đề cập của bài này, nhưng đây là những gì diễn ra ở một level rất cao: Spotify thu thập dữ liệu từ các web một cách liên tục để tìm thông tin về các bài blog và những văn bản viết khác về âm nhạc, sau đó khám phá ra những gì mà mọi người nói về những nghệ sĩ hay bài hát cụ thể — cái mà phụ thuộc và ngôn ngữ thường xuyên được sử dụng trong những bài hát này, và những nghệ sĩ và những bài hát khác cũng được bàn luận đến bên cạnh chúng.
Tôi vẫn chưa hiểu chính xác cách mà Spotify chọn để xử lý dữ liệu được lấy về, nhưng tôi có thể giúp bạn hiểu cách mà Echo Nest đã sử dụng để xử lý chúng. Họ sẽ chia những dữ liệu này vào những cái mà họ gọi là “cultural vectors” hoặc “top terms”. Mỗi nghệ sĩ và bài hát có hàng nghìn những top terms thay đổi hàng ngày. Mỗi term có một liên kết mạnh mẽ (a weight associated), cái sẽ tiết lộ tầm quan trọng của mô tả (có xác suất một ai đó sẽ mô tả âm nhạc như những term).
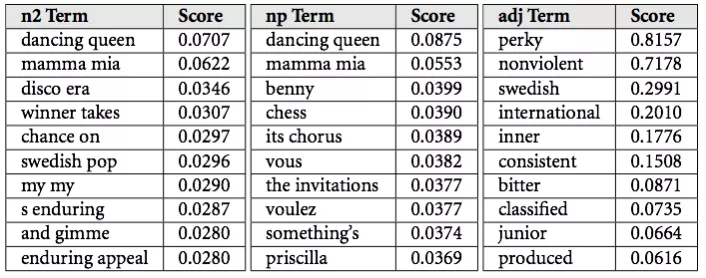
Sau đó, gần như collaborative filtering, the NLP model sử dụng những terms này và sức nặng của chúng để tạo nên một vector thể hiện của bài hát có thể được sử dụng để xác định nếu có hai mảnh của âm nhạc tương đồng (determine if two pieces of music are similar). Cool, right?
Recommendation Model #3: Raw Audio Models
Câu hỏi đầu tiên. Bạn có thể đang nghĩ:
“Nhưng, Sophia này, chúng ta đều có rất nhiều dữ liệu từ hai model đầu tiên rồi! Tại sao chúng ta cần phân tích audio nữa?”
Well, đầu tiên, có thêm model thứ 3 này giúp cải thiện tính chính xác của dịch vụ recommendation tuyệt vời này (this amazing recommendation service). Nhưng thực tế thì, model này phục vụ cho 2 mục đích. Không như 2 model đầu tiên, raw audio modeal take into account new songs.
Ví dụ, bài hát mà người bạn của bạn sáng tác, đồng thời cũng là người thể hiện (sing-songwriter) xuất hiện trên Spotify. Có thể nó chỉ có 50 lượt nghe, vì thể sẽ có không nhiều người nghe để collaborative filtering nó. Nó cũng không được nhắc tới ở bất cứ đâu trên internet, vì thế NLP models sẽ không biết đến nó. Tin vui là, raw audio models không phân biệt giữa new tracks và popular tracks, vì thế với sự giúp đỡ của raw audio models bài hát của người bạn kia có thể xuất hiện trong một Discovery Weekly playlist bên cạnh những bài hát phổ biến.
Ok, bây giờ đến câu hỏi “như thế nào” — Chúng ta có thể phân tích raw audio data như thế nào, khi mà điều này nghe có vẻ rất trừu tượng?
… Bằng mạng lưới neural xoắn (convolutional neural networks)
Convolutional neural networks là một công nghệ tương tự bên cạnh công nghệ nhận diện khuôn mặt. Với trường hợp của Spotify, họ đã điều chỉnh để sử dụng audio data thay vì pixels (các điểm ảnh). Đây là một ví dụ của một cấu trúc mạng lưới neural (a neural network architecture):
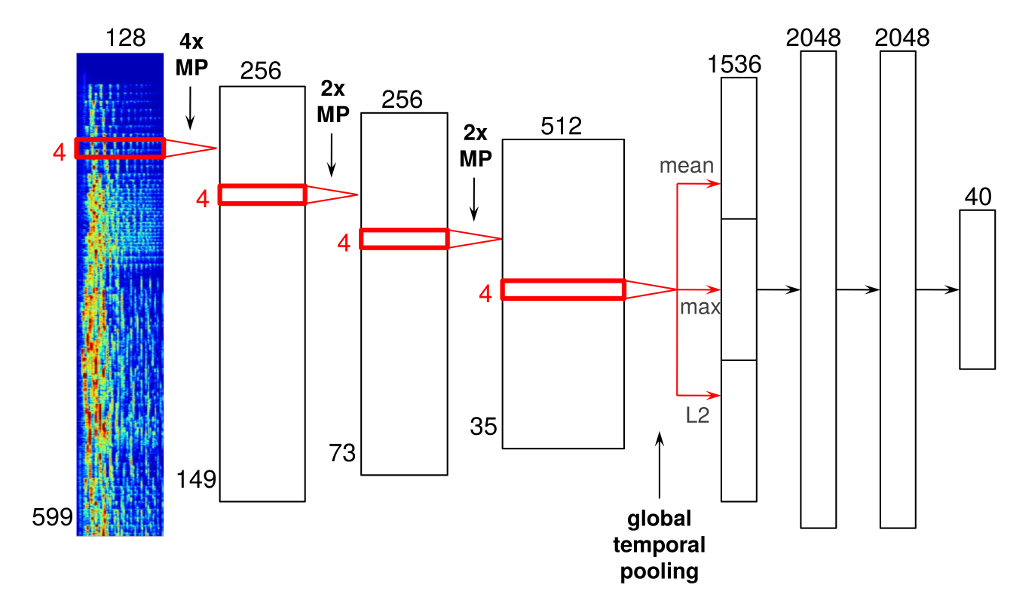
Mạng lưới neural cụ thể này có 4 convolutional layers (4 lớp xoắn), như thanh dày ở bên trái, và 3 lớp dày đặc, như những thanh mỏng ở bên phải. The input are time-frequentcy đại diện cho audio frames (khung âm thanh), những cái mà sau đó sẽ nối lại để tạo nên quang phổ.
The audio frames đi xuyên qua những convolutional layers, và sau đó là convolutional layers cuối cùng, bạn có thể thấy một “global temporal pooling” layer (layer tập hợp toàn bộ tạm thời), cái tập hợp đi xuyên qua trục thời gian, có tác động hiệu qua đến những số liệu thông kê về tính toán của những tính năng đã được học xuyên qua thời gian của bài hát (effectively computing statistics of the learned features across the time of the song).
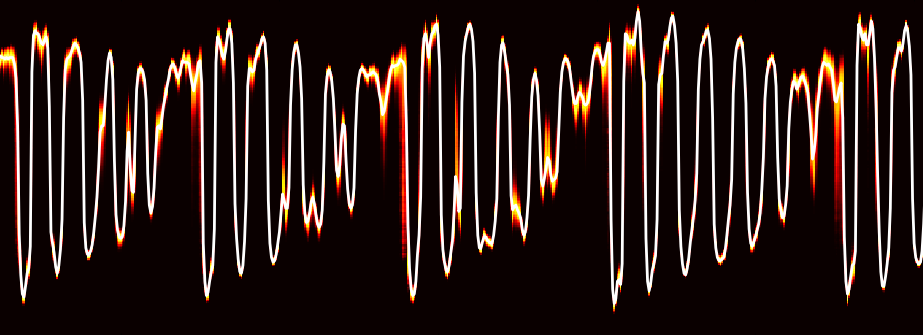
Sau quy trình này, the neural network sẽ nói ra những hiểu biết về bài hát, bao gồm những đặc điểm như ước tính time signature, key, mode, tempo, và loudness. Ở dưới là chỗ của dữ liệu này trong 30 giây trích từ một đoạn trong bài “Around the World” của Daft Punk.
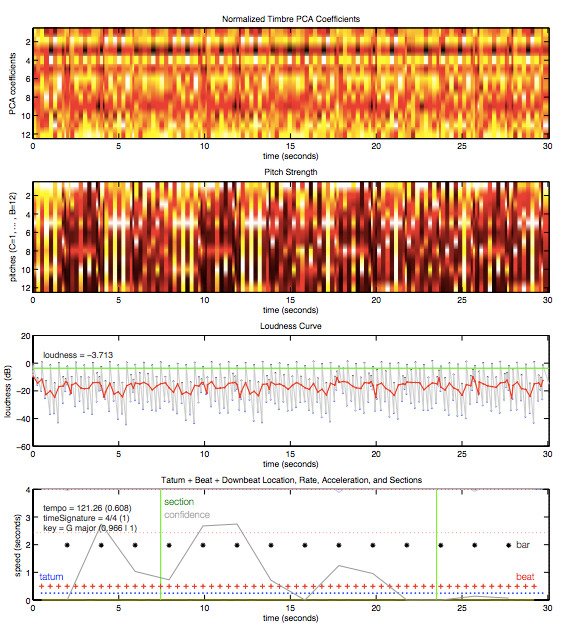
Cuối cùng,sự hiểu biết về những đặc điểm quan trọng của bài hát cho phép Spotify hiểu được những điểm tương đồng cơ bản giữa những bài hát và vì thế, người dùng có thể thích những bài hát có những nét tương đống này dựa trên lịch sử nghe nhạc của họ.
Vừa rồi là những gì cơ bản nhất của 3 recommendation models chính của the recommendations pipeline, và cuối cùng là sức mạnh của the Discover Weekly playlist!
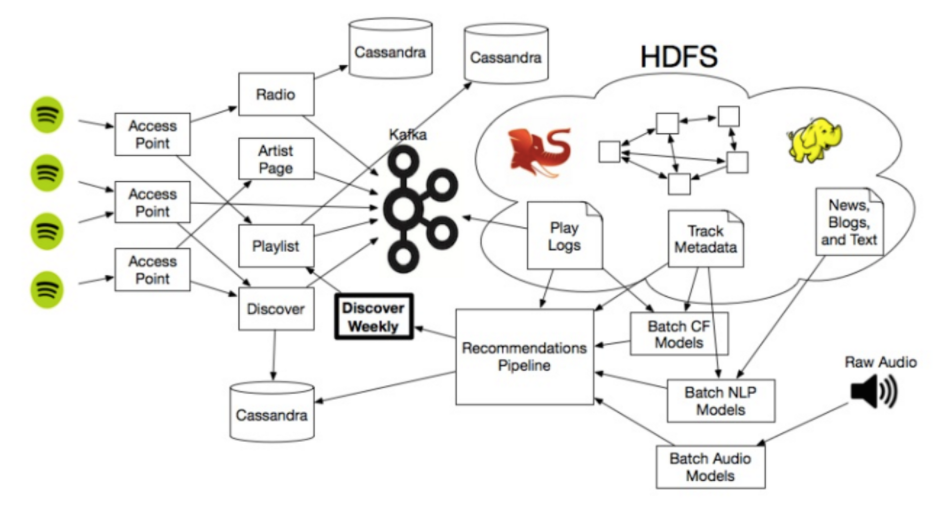
Tất nhiên, những recommendation model này đều kết nối với hệ sinh thái rất rộng của Spotify, bao gồm một kho dữ liệu khổng lồ và sử dụng rất nhiều Hadoop clusters để tăng recommendations và đảm bảo những cỗ máy này hoạt động được trên những ma trận khổng lồ, cũng như trên thế giới âm nhạc trực tuyến bất tận, và một số lượng cực lớn các audio files.
Tôi hi vọng bài viết này đã cung cấp thông tin và “xử lý” (tickled) sự tò mò của bạn như nó đã xảy ra với tôi. Bây giờ, tôi sẽ tiếp tục khám phá Discover Weekly, tìm những bài hát yêu thích mới, hiểu và trân trọng all the machine learing that’s going on behind the scenes.
— — —
Sources:
— From Idea to Execution: Spotify’s Discover Weekly (Chris Johnson, ex-Spotify)
— Collaborative Filtering at Spotify (Erik Bernhardsson, ex-Spotify)
— Recommending music on Spotify with deep learning (Sander Dieleman)
— How music recommendation works — and doesn’t work (Brian Whitman, co-founder of The Echo Nest)
— Ever Wonder How Spotify Discover Weekly Works? Data Science (Galvanize)
— The magic that makes Spotify’s Discover Weekly playlists so damn good (Quartz)
— The Echo Nest’s Analyzer Documentation
— From Idea to Execution: Spotify’s Discover Weekly (Chris Johnson, ex-Spotify)
— Collaborative Filtering at Spotify (Erik Bernhardsson, ex-Spotify)
— Recommending music on Spotify with deep learning (Sander Dieleman)
— How music recommendation works — and doesn’t work (Brian Whitman, co-founder of The Echo Nest)
— Ever Wonder How Spotify Discover Weekly Works? Data Science (Galvanize)
— The magic that makes Spotify’s Discover Weekly playlists so damn good (Quartz)
— The Echo Nest’s Analyzer Documentation
Thanks also to ladycollective for reading this article over and suggesting edits.

maingocanh
@maingocanh
Khoa học - Công nghệ
/khoa-hoc-cong-nghe
Bài viết nổi bật khác
- Hot nhất
- Mới nhất