
Trước khi có 'Attention Is All You Need'
Hay ngành dịch đã đóng góp cho LLM như thế nào?
Phần lớn kiến trúc LLM hiện đại đứng trên vai Transformer và Transformer thì được biết đến rộng rãi qua bài báo Attention Is All You Need. Tuy nhiên bài viết này không đi sâu vào bài báo đó. Tôi muốn nói về đoạn trước khi người ta đi đến attention: những điểm đau trong một ngành khác, cụ thể là ngành dịch, đã khiến attention trở thành một ý tưởng gần như tất yếu.
Trước hết, nói một cách đơn giản, attention là cơ chế cho phép model không xử lý mọi phần của đầu vào như nhau. Khi sinh ra một từ ở đầu ra, model có thể “nhìn” mạnh hơn vào một số phần nhất định của câu nguồn. Nói kỹ thuật hơn, attention cho phép model học trọng số khác nhau cho các phần khác nhau của input, thay vì nén toàn bộ câu vào một biểu diễn cố định rồi hy vọng decoder tự xoay xở với phần còn lại.
Lịch sử của attention vì thế không phải câu chuyện một thiên tài đột nhiên nghĩ ra Transformer như Linus nghĩ ra Git. Nó giống một chuỗi quan sát, tìm điểm đau, xử lý điểm đau, rồi lại tiếp tục vòng lặp đó. Điểm đau lớn nhất trong chuỗi này lại nằm ở Machine Translation, một ngành tôi từng làm việc tương đối lâu với tư cách CAT/MT Engineer, trước khi chuyển hẳn sang SWE.
Khoảng cuối năm 2013, khi còn làm cho một công ty lớn trong ngành Translation & Localization, tôi được (hoặc bị) giao vào một dự án Machine Translation khá tiên phong ở thời điểm đó, dùng công nghệ của Microsoft (Microsoft Translator Hub, được đưa vào sử dụng vào năm 2012). Để giảm rủi ro triển khai, trưởng dự án chọn một cặp ngôn ngữ được kỳ vọng có chất lượng cao đối với TM hiện có của công ty: Đức–Anh (về cơ chế của TM, bạn có thể đọc ở đây). Khi ấy, workflow trong các công ty bản địa hoá vẫn chủ yếu xoay quanh Statistical Machine Translation (SMT), Translation Memory và Term Base. Neural Machine Translation chưa phải thứ mà người làm localization có thể mặc nhiên gọi API rồi dùng như bây giờ.
Kết quả: Dự án thất bại thảm hại. Cho dù dùng TM với độ chính xác cao, thậm chí đi cùng với Post Editing (MTPE - Machine Translation Post Editing, vẫn là một workflow rất phổ biến trong ngành bản địa hoá), thì chất lượng bản dịch vẫn bị đánh giá là “không thể chấp nhận được”. Trưởng dự án cong đít lên đổ lỗi cho đám MT Engineer là chuẩn bị không kỹ, đám Engineer ngồi họp với nhau cãi nhau với quản lý dự án ỏm tỏi là chúng tao làm kỹ lắm rồi, bằng chứng đây, đưa ra toàn TM với độ trùng (match) hầu như là 90%. Rồi đội ngôn ngữ vào cuộc. Phát hiện ra một điều: các câu dài hoàn toàn mất ngữ cảnh, cho dù ngữ cảnh đã được quy định rất rõ trong MT Engine là câu trước và câu sau. Tất cả ôm nhau khóc. Đội Vendor Management cuống cuồng đi tìm người dịch để làm dịch tay (HT - Human Translation). Dự án lỗ chổng vó.
Vậy thì bài học ở đâu? Là ở cơ chế “hiểu”. SMT của Microsoft Translator Hub thất bại vì lý do kỹ thuật segments được xử lý độc lập với nhau. Không có cơ chế nào để giữ ngữ cảnh xuyên suốt một đoạn dài. Khi người dịch, họ sẽ có một mô hình tư duy nhất quán để luôn luôn kiểm tra lại ngữ cảnh của không chỉ câu mà cả đoạn trước, nhưng máy thì không.
Vấn đề này không chỉ ngành bản địa hoá gặp. Giới nghiên cứu cũng gặp vấn đề tương tự. Năm 2014, Ilya Sutskever và đồng nghiệp tại Google Brain công bố paper 'Sequence to Sequence Learning with Neural Networks' nhằm đề xuất một kiến trúc khác hoàn toàn: RNN encoder-decoder thay vì phrase-based statistics.
Trước attention: RNN và cái sự “hiểu” của máy
Trước 2014, dịch máy dùng sequence-to-sequence với kiến trúc tương tự Recurrent Neural Network - RNN (Sutskever et al., 2014), cấu trúc của nó như sau:
- Encoder RNN đọc câu nguồn, ví dụ như “I love cats” từng từ một, cập nhật một trạng thái ẩn (hidden state) vào sau mỗi từ.
- Sau từ cuối, trạng thái ẩn cuối cùng sẽ trở thành vector duy nhất đại diện cho toàn câu.
- Decoder RNN lấy vector đó, sinh ra câu đích “Tôi yêu mèo” từng từ một

Context Vector (Vector chứa ngữ cảnh của câu) ở trong trường hợp này thường có kích thước cố định, thường là 1000 chiều. Khi xử lý một câu 3 từ, kích thước này đủ, nhưng khi phải xử lý một câu 40 từ, h2 sẽ bị nén quá mức, khiến việc mất đi ngữ cảnh của câu là không thể tránh khỏi. Trong lượng thông tin bị mất đấy nhiều khi là có cả thông tin phần đầu câu, vì h3 lại nén thêm một lần nữa.
Quan sát 1: Câu dài khiến điểm BLEU (Bilingual Evaluation Understudy - Điểm đánh giá chất lượng dịch máy) giảm thê thảm
Bahdanau và Cho (Đại học Montreal, 2014) phát hiện: điểm BLEU giảm mạnh khi câu đầu vào dài hơn 30-40 từ. Lý do trực giác:
Toàn bộ ý nghĩa của một câu 50 từ phải nén vào một vector cố định 1000 chiều. Khi decode đến từ thứ 30, encoder đã quên từ đầu câu.
Đây gọi là nghẽn cổ chai về mặt truyền đạt thông tin (information bottleneck).
Quan sát 2: Con người không dịch theo kiểu đó
Như đã nói ở đoạn trên, dịch giả chuyên nghiệp thông thường không bao giờ dịch theo kiểu của máy. Họ không đi đọc hết toàn bộ cuốn sách rồi đi dịch từ trí nhớ. Họ nhìn lại câu ở ngôn ngữ nguồn (source language) liên tục khi dịch. Đây cũng là lý do mà định dạng cho file dịch trong ngành bản địa hoá luôn là file bilingual với hai cột source (nguồn) và target (đích). Đặc biệt với các câu hay đoạn dài, họ sẽ phải nhảy qua nhảy lại, đối chiếu liên tục giữa từ với đoạn, đoạn với đoạn, đoạn với toàn bộ văn bản.
“Ngành bản địa hoá đã thiết kế các phần mềm dịch có máy hỗ trợ (CAT - Computer Assisted Translation) quanh hành vi này từ thập niên 90, mọi công cụ CAT (Trados, MemoQ, Wordfast) đều dùng dạng hai cột source-target (nguồn-đích), vì dịch giả cần nhìn lại source liên tục khi sinh target. Công cụ CAT đã được thiết kế để hỗ trợ cơ chế này của dịch giả, hai mươi năm trước khi Bahdanau hình thức hoá nó thành một bài báo khoa học trong lĩnh vực học máy.”
Đây là một quan sát thật mà Bahdanau sử dụng để làm căn cứ cho nghiên cứu. Không phải công thức toán học, là hành vi thật của con người.
Bahdanau attention — nghiên cứu năm 2014 (đây là khoảnh khắc mà “attention” ra đời)
Bài báo nghiên cứu của Bahdanau có tên "Neural Machine Translation by Jointly Learning to Align and Translate" — Bahdanau, Cho, Bengio. ICLR 2015.
Ý tưởng: Thay vì decoder chỉ thấy một vector cuối cùng (h3), giờ sẽ cho decoder thấy tất cả các trạng thái ẩn (từ h1 → h3) của encoder. Mỗi một bước decode, decoder sẽ tự quyết định “bây giờ tôi cần phải chú ý vào từ nào trong câu ở ngôn ngữ nguồn.”
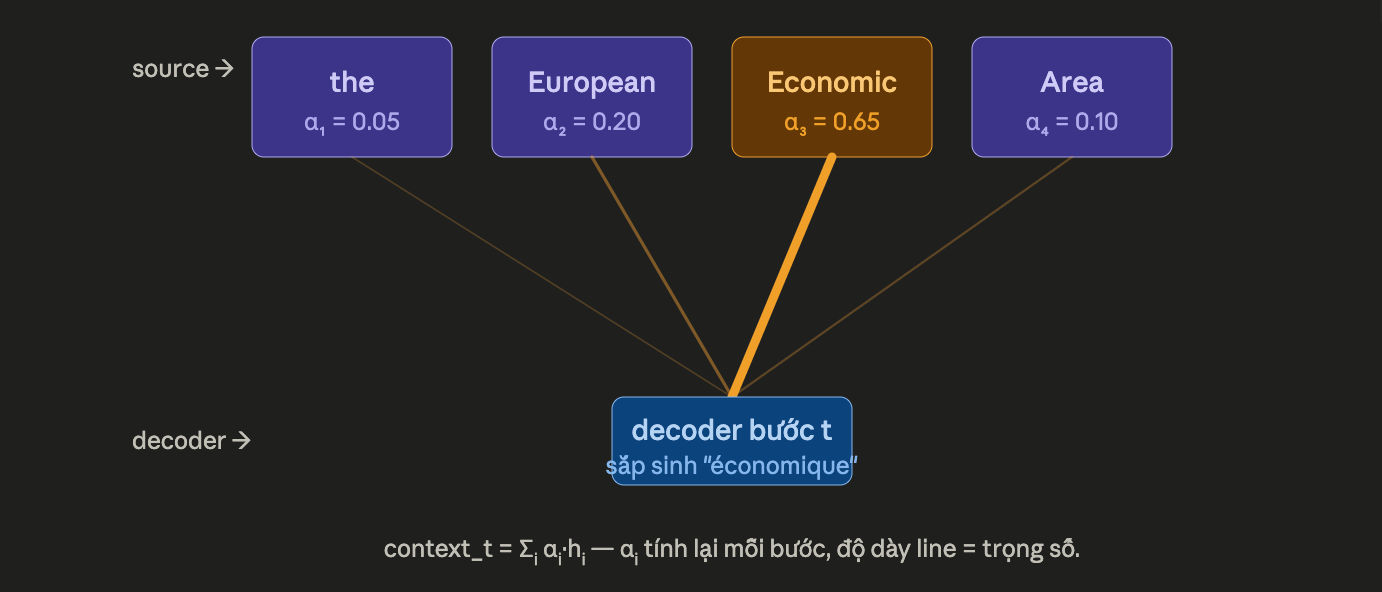
Cơ chế cụ thể:
- Encoder vẫn chạy, nhưng giữ lại hidden state ở mọi vị trí (một vector cho mỗi một từ ở câu ngôn ngữ nguồn) chứ không chỉ ở mỗi vị trí cuối nữa.
- Decoder, khi sinh từ thứ t, làm vài việc:
1. Tính một điểm giữa trạng thái của decoder hiện tại so với hidden state của encoder. Điểm này = “từ trong câu nguồn có liên quan nhiều hay ít đến từ tôi sắp dịch?”
2. Thực hiện một hàm softmax trên tất cả các điểm đấy để đưa ra một phân phối xác suất (gọi là attention weights - trọng số chú ý)
3. Tính tổng có trọng số của tất cả các trạng thái của encoder theo phân phối này để đưa ra một vector ngữ cảnh (context vector)
Decode bằng cách dùng context vector này
Khi biểu diễn ra thì sẽ thế này:
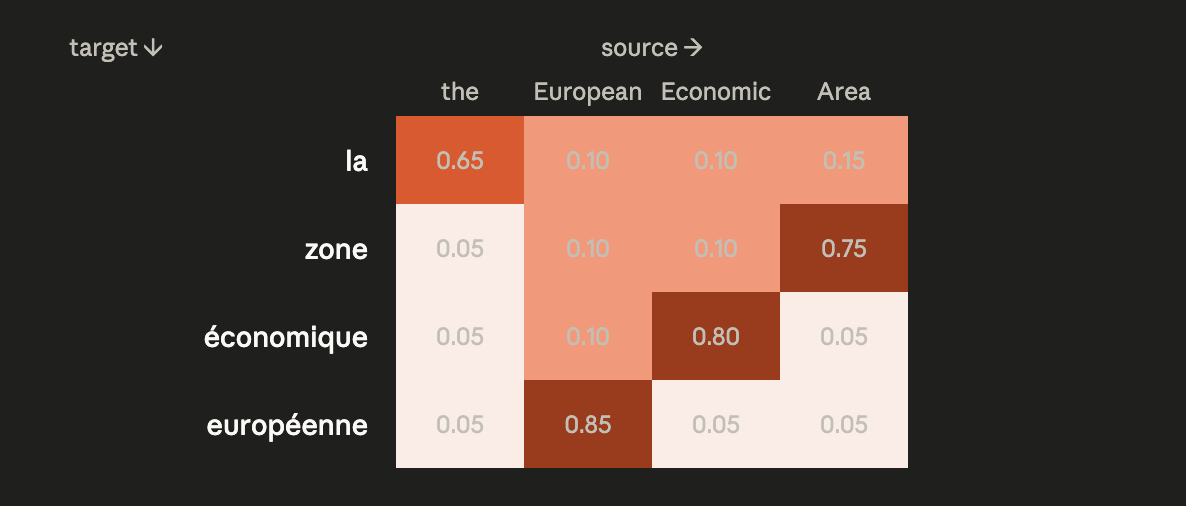
Và biểu diễn này khiến cả cộng đồng “WTF”. Bởi khi dựng thành heatmap kiểu này, người ta thấy rõ ràng sự liên kết giữa từ nguồn với từ đích. Ví dụ trong dịch từ tiếng Anh → tiếng Pháp:
- Khi dịch “European”, attention weights tập trung vào “European” trong câu gốc
- Khi dịch “Economic”, nó lại tập trung vào “Economic”
- Với cụm có trật tự đảo “the European Economic Area”, nó tự học cách đảo, để biến thành “la zone économique européenne”
Vấn đề là: không ai bảo mô hình làm thế. Mô hình tự suy ra được liên kết chỉ từ việc training trên cặp câu dịch. Đây là khoảnh khắc mà cả ngành “eureka”, khi lần đầu có một cơ chế vừa cải thiện được hiệu năng lại vừa có thể giải thích được rõ ràng. Đây chính là hình thức sơ khởi của attention. Chưa có khái niệm “head” được đưa vào.
2015-2016: cơ chế attention lan ra khắp NLP (Natural Language Processing - xử lý ngôn ngữ tự nhiên)
Sau Bahdanau, cơ chế attention được áp dụng vào tất cả các loại tác vụ:
- Luong attention (2015) - Stanford. Đơn giản hoá Bahdanau, cho phép nhiều loại hàm tính điểm khác nhau.
- Show, Attend and Tell (Xu et al., 2015) - chú thích ảnh. Cơ chế attention giúp máy nhìn vào các vùng của ảnh khi sinh ra chú thích.
- Pointer Networks (Vinyals, 2015) - dùng attention để chọn ra phần tử
- Memory Networks (Mạng lưới ghi nhớ thông tin) — attention làm cơ chế đọc/ghi và bộ nhớ
Lúc này, attention từ một cơ chế đã trở thành một module bổ sung cho RNN. Và từ đây dẫn đến một vài quan sát.
Quan sát 3: Một attention là không đủ
Khi có một lớp attention duy nhất, attention weights là một phân phối duy nhất trên mọi vị trí. Mô hình bắt buộc phải chọn: giờ sẽ tập trung vào đối tượng nào trong câu? Vào từ đầu tiên? Hay vào dấu chấm? Chỉ có thể chọn một vì softmax sẽ dồn xác suất.
Tuy vậy, ngôn ngữ tự nhiên có nhiều loại quan hệ:
- Quan hệ cú pháp (chủ ngữ-vị ngữ)
- Quan hệ ngữ nghĩa (từ đồng nghĩa, khác nghĩa)
- Quan hệ vị trí giữa các từ
- Quan hệ đồng tham chiếu (khi hai hay nhiều từ hoặc cụm từ khác nhau cùng chỉ đến một đối tượng duy nhất)
Một lớp attention không thể nào đồng thời nhìn vào tất cả các loại quan hệ đó. Nó luôn bị ép phải chọn một loại trong một lớp
Quan sát 4: Chia chiều, không tăng chiều
Cách sửa đơn giản nhất cho quan sát 3 là chạy nhiều lớp attention riêng biệt, mỗi cái học một loại quan hệ. Tuy nhiên điều này ảnh hưởng đến hiệu năng rất nhiều, vì giả sử với bốn loại quan hệ kia, mỗi một lớp attention sẽ là thêm bốn ma trận
d x d, phải tính toán thêm. Vaswani et al. trong nghiên cứu “Attention is All You Need” đã giải quyết việc này bằng một cách rất thông minh: chia chiều của một ma trận thay vì thêm ma trận.
Nếu như
d = 512, thay vì có một attention học trên toàn 512 chiều, cho 8 attention chạy song song, mỗi cái học trên 64 chiều ( 512 / 8 = 64). Số lượng tham số giữ nguyên, kích thước của ma trận không đổi, vẫn là 512 x 512, nhưng mỗi “head” độc lập học một loại quan hệ khác nhau. Phép toán cụ thể tôi sẽ không nhắc lại ở đây vì trong nghiên cứu có ghi rõ. Vậy tại sao chia chiều lại hoạt động?
Về mặt trực giác:
Một không gian 512 chiều có đủ chỗ cho nhiều “subspace” (không gian con) 64 chiều, mỗi subspace có thể encode một loại thông tin khác nhau.
Nếu phải so sánh, nó sẽ giống như RGB trong ảnh. Bạn có ba kênh màu trong cùng một ảnh, mỗi một kênh sẽ encode một loại thông tin (đỏ, xanh lá, xanh dương). Bộ não xử lý ba kênh cùng lúc, chứ không chia kênh độc lập. Khái niệm “head” đã làm điều tương tự với attention.
Về mặt bằng chứng, điểm BLEU được cải thiện nhiều nhất ở con số 8 heads. Quá nhiều head, mỗi head sẽ có quá ít chiều, sẽ khiến cho hiệu năng tổng thể bị giảm. Head bổ sung về mặt chuyên biệt hoá cho attention, khiến bức tranh trở nên hoàn chỉnh hơn. Multi-head attention hoàn thành Transformer. Phần còn lại như scale, pretraining, RLHF, v.v và mây mây là câu chuyện của những năm sau.
Túm cái váy: Chuỗi quan sát và sửa lỗi
- 2014: RNN bị nghẽn cổ chai khi câu dài → attention ra đời để cho decoder “nhìn lại” encoder.
- 2014-2016: attention lan khắp NLP, vẫn dùng xương sống là RNN.
- 2017: “Attention is All You Need”: bỏ RNN, attention làm cơ chế chính. Phát hiện một attention không đủ → chia chiều thành multi-head để học nhiều loại quan hệ song song.
- 2018+: Phân tích thực nghiệm xác nhận việc các head thực sự có khả năng chuyên môn hóa, chứng thực trực giác.
Cái hay của chuỗi này, đấy là không có “thiên tài nghĩ ra Transformer.” Có một chuỗi người đi sửa một điểm đau cụ thể, mỗi bước hoàn thiện bước trước. Bahdanau sửa để tránh nghẽn cổ chai. Luong đơn giản hoá cơ chế. Vaswani gộp tất cả lại và thêm multi-head + positional encoding + bỏ RNN. Mỗi quyết định có một quan sát rất cụ thể đứng sau.
Đây cũng là cách kiến thức trong ngành ML được tạo ra, không phải là từ tư duy nguyên bản (first principles) thuần tuý, mà từ chuỗi quan sát thực tế: làm thử, cho chạy, đo lỗi, sửa, chạy lại. Tất cả đều sinh ra từ một ông B nào đó nhìn ông A trước làm thấy “ngứa mắt”, rồi sửa, rồi ông C sau lại thấy ông B còn ngứa mắt hơn, cho đến thằng tôi đây ngồi tổng hợp hết mấy cái ngứa mắt vào một chỗ.
Bài gốc:


The Merc
@TheMerc
Khoa học - Công nghệ
/khoa-hoc-cong-nghe
Bài viết nổi bật khác
- Hot nhất
- Mới nhất