
Kiến thức cơ bản về partitioned table trong Database
Partitioning là 1 giải pháp tối ưu đối với những bảng lớn đến rất lớn, giúp tối ưu hiệu năng và công sức quản lý. Trong bài viết này, tôi sẽ giải thích cho các bạn lý do tại sao chúng ta cần đến Partitioned Table nhé.

Giới thiệu
Trên thực tế, khi bạn làm việc với các database lớn, sẽ rất hay bắt gặp 1 loại bảng gọi là Partitioned Table, bên cạnh các bảng bình thường khác.
Partitioning là 1 giải pháp tối ưu đối với những bảng lớn đến rất lớn, giúp tối ưu hiệu năng và công sức quản lý.
Trong bài viết này, tôi sẽ giải thích cho các bạn lý do tại sao chúng ta cần đến Partitioned Table nhé.
Đặt vấn đề
Một table bình thường (hay non partitioned), bạn hình dung, nó giống như 1 khối dữ liệu khi lưu trên ổ đĩa cứng.
Table càng lớn, thì khối dữ liệu cũng càng lớn, khiến cho các truy vấn trên khối dữ liệu đó cũng khó khăn và chậm chạp hơn.
Với bài toán này. có 2 cách xử lý chính để tối ưu hóa thời gian truy vấn:
- Đánh index cho bảng dựa trên 1 cột nào đó:Cách này rất hiệu quả nếu dữ liệu cần lấy là nhỏ so với tổng dữ liệu trong bảng. Tuy nhiên, dữ liệu tăng trưởng đến 1 mức độ nào đó, cách xử lý này cũng sẽ giảm dần hiệu quả. (do bản thân index cũng sẽ lớn theo dữ liệu thực sự)
- Chia để trị (hay partitioning):Với cách này, từ 1 khối dữ liệu to ban đầu, chúng ta sẽ chia nhỏ nó ra thành các khối nhỏ hơn, để tiện cho việc quản lý. Hay nói 1 cách khác, chúng ta đã partition bảng ban đầu!
Và partitioned table cũng chính là chủ đề của bài viết này.
Partitioned Table là gì?
Partitioned Table là 1 bảng đã được chia nhỏ thành các phần (hay các partition) theo 1 cột nào đó trong bảng.
Ví dụ như sau:
Table Ban_hang có cấu trúc như sau:
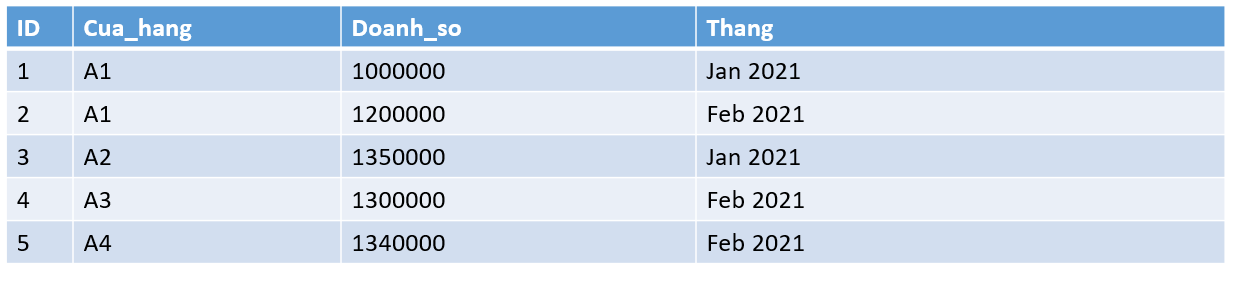
Nếu như bây giờ tôi thực hiện câu lệnh sau:
select * from ban_hang where cua_hang='A1' and thang='Jan 2021';Để tìm được các dòng dữ liệu có cột cua_hang=’A1′ và thang=’Jan 2021′, RDBMS sẽ cần quét toàn bộ bảng để lấy ra các dòng thỏa mãn điều kiện.
Trong ví dụ trên, sẽ có 5 dòng dữ liệu cần phải quét qua. Nếu bảng lớn, thời gian này sẽ rất lâu.
Bằng cách chia nhỏ bảng Ban_hang ra theo 1 tiêu chí (hay 1 cột) mà chúng ta chọn, vấn đề này sẽ được giải quyết!
Chú ý: Cột được lựa chọn là tiêu chí để chia nhỏ bảng, ta gọi đó là partition key
Giả sử, chúng ta chia bảng theo cột Cua_hang (partition key là Cua_hang) thì bảng sẽ có 4 phần: A1, A2, A3, A4 tương ứng với 4 partition
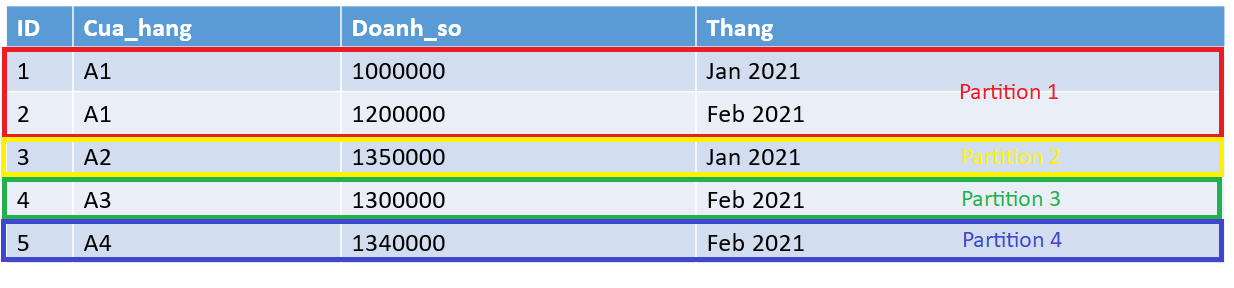
Như vậy, câu lệnh:
select * from ban_hang where cua_hang='A1' and thang='Jan 2021';sẽ chỉ cần quét dữ liệu của Partition 1 thôi. Chỉ còn 2 dòng cần quét qua, so với 5 dòng như trước khi bảng được partition. Nhanh hơn nhiều phải không?
Còn nếu chúng ta chia bảng theo cột Thang (partition key là Thang) thì sẽ có các partition như sau:
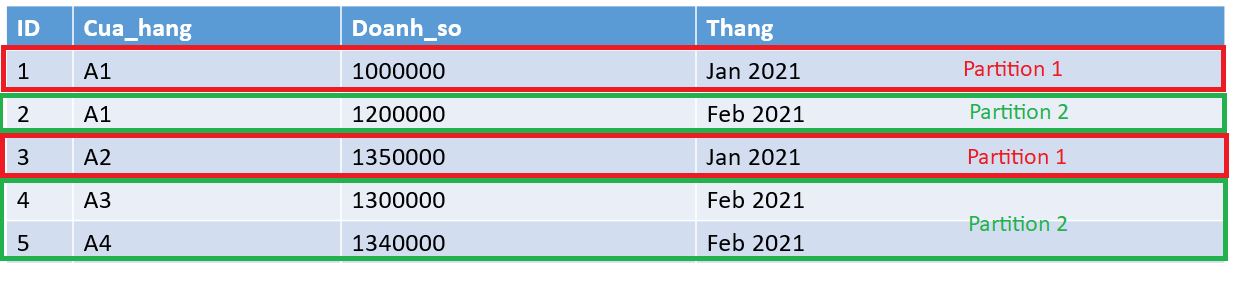
Cũng tương tự như vậy, chỉ có 1 partition (hay 2 dòng dữ liệu) được quét qua, thay vì toàn bộ bảng.
Nhìn ở góc độ vật lý, bảng non-partition và partition trông sẽ như thế này.
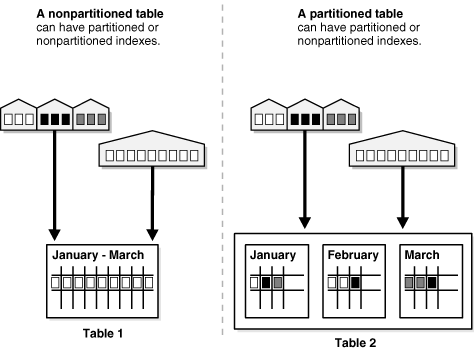
Khi nào bảng nên được partition?
Như vậy, các bạn đã hiểu được mức độ quan trọng của Partitioned Table. Song, nếu Partitioned Table giúp tối ưu hiệu năng như vậy, sao chúng ta không mặc định tạo bảng ở dạng partition luôn đi.
Câu trả lời là: Không phải tình huống nào partitioned table cũng phát huy được ưu thế của mình!
Quay lại ví dụ bên trên, nếu câu lệnh truy vấn bây giờ là:
select * from ban_hang where doanh_so > 1000000;Điều kiện lọc dữ liệu không có đủ thông tin để RDBMS lựa chọn partition nào cần quét qua, do đó, partitioned table trong tình huống này không có tác dụng.
Dưới đây là 1 số hướng dẫn khi nào bạn nên cân nhắc 1 bảng nên được partition (Mình lấy theo tài liệu của Oracle):
- Table có dung lượng từ 2GB trở lên nên cân nhắc được partition.
- Table có chứa dữ liệu lịch sử. Dữ liệu cũ, ít được sử dụng sẽ đưa vào các partition cũ, những dữ liệu mới sẽ được đưa vào partition mới.
- Table có nội dung có thể được chia thành các khu vực có mức độ ưu tiên khác nhau (VD: khu vực dành cho dữ liệu thường xuyên được truy vấn,hoặc ít được truy vấn, …)

mrduydx
@mrduydx
Khoa học - Công nghệ
/khoa-hoc-cong-nghe
Bài viết nổi bật khác
- Hot nhất
- Mới nhất